

Наталія Федоренко
Вебаналітик у PROANALYTICS.TEAMData-driven атрибуція та досвід практичного використання
Почнемо статтю з дисклеймера: окрім технічної й об’єктивної сторони – визначень, пояснень принципів моделей і т. п. – текст, який я пропоную вам прочитати, буде містити в собі мої суб’єктивні думки.
Отже, план на сьогодні насичений:
Чому я написала цю статтю
Поділитися досвідом, про що вказано в назві статті, — не єдина моя мета. На додачу я ще хочу наштовхнути вас на певні думки та, можливо, спробувати розвіяти туман таємничої загадковості навколо того, що прийнято називати data-driven атрибуцією. Інколи у спілкуванні з клієнтами, які цікавляться чимось подібним, мені виглядає, що приставка “data-driven” додає “експертної експертності” до рішень на основі такої атрибуції. Схоже, що ми вже призвичаїлися до того, що рішення мають бути “data-driven”, тобто в перекладі “на основі даних”. І я підтримую це, але підходити до цього треба критично, а не бездумно.
При цьому, на жаль, рідко коли усвідомлюють обмеження таких моделей та вимоги, яких потрібно дотримуватися, щоб модель насправді дала цінні інсайти, а не тихо вводила в оману. Про атрибуцію “на основі даних” сказано вже так багато позитивного, що вже здається, що ця модель є єдиною правильною для всіх без винятку, проте далеко не всі можуть собі її “дозволити”, оскільки, як і будь-яка модель на основі машинного навчання, вона вимагає консистентних даних у достатній кількості. Без дотримання цієї умови ви все одно отримаєте “data-driven” результати, але з великою вірогідністю вони будуть далекі від правди, про що модель вам, звісно, не скаже, а в кращому випадку залишить вас наодинці з питанням: “а чи можу я вірити цим результатам та приймати важливі для бізнесу рішення на їхній основі?”.
Щодо консистентності даних – для цього важливо не забувати коректно розмічати трафік, щоб побачити вплив відповідних каналів. Про принципи коректної розмітки рекомендую прочитати цю статтю з можливістю отримати шаблон UTM-розмітки від нашої команди.
Що таке data-driven атрибуція
Зазвичай про data-driven атрибуцію (DDA) можна прочитати, що це – найсучасніша модель розподілу цінності конверсії між різними точками контакту (каналами), з якими взаємодіяв користувач перед покупкою. Але насправді це не одна модель, це принцип розподілення цінності.
Принципів існує 2:
- на основі правил – rule-based
- і на основі даних – data-driven.
Відмінність полягає в тому, в який момент відомі коефіцієнти розподілення цінності конверсії. У принципу на основі правил вони відомі ще до її застосування. Це такі моделі, як:
- останній непрямий клік – 100% цінності призначається останньому відомому джерелу перед конверсією,
- лінійне розподілення – всі джерела, які брали участь у досягненні конверсії, отримують рівну долю цієї конверсії,
- на основі позиції – перше й останнє джерело отримують по 40% цінності, а між середніми рівномірно розподіляється решта 20%,
- залежно від давності взаємодії – чим джерело ближче до конверсії, тим більшу долю цінності воно отримує,
- перший клік – вся цінність атрибутується джерелу першого або першого непрямого кліку на сайт або додаток у вікні атрибуції*.
*Окрім цього визначення, також можна зустріти, що це джерело першого входу на сайт або в додаток. Але важливою особливістю всіх моделей є наявність у них вікна атрибуції, тобто періоду до конверсії, і всіх торкань, які трапилися в цей період. Класично моделі атрибуції розраховуються у вікні в 30 або 90 днів до конверсії. При цьому період може бути будь-яким – все залежить від того, скільки потрібно часу вашому потенційному клієнту, щоб вирішити сконвертуватися, і вашого рішення стосовно того, протягом якого періоду на залучення такого клієнта, на вашу думку, могли впливати “торкання” з вашою пропозицією.
Всі ці правила не залежать від даних і спільні для всіх, хто впроваджує такий підхід.
Data-driven принцип полягає в тому, що сама модель визначає коефіцієнти розподілення цінності в процесі навчання на даних, які їй надаються. Таким чином, ці коефіцієнти у кожної моделі свої, і вони можуть (а взагалі-то повинні мати змогу) змінюватися з часом навіть у межах одного проекту. Тому для DDA критично важлива якість і достатня кількість даних, бо саме вони визначають розподілення цінності й усі ті плюси, які може мати такий підхід у порівнянні з rule-based. “Може”, але не обов’язково “буде” мати.

Яка data-driven модель в GA4
Я не знаю :)
Тобто не можу сказати, на основі конкретно якої моделі машинного навчання базується DDA в GA4. Довідка “говорить” загальними фразами, як-от:
"Методика атрибуції на основі даних передбачає два основні етапи:
- аналіз доступних даних про шляхи до ключових подій і розробка моделей коефіцієнтів конверсій для кожної ключової події;
- використання прогнозів моделі коефіцієнта ключової події як вхідних даних для алгоритму, що призначає відсоток цінності різним взаємодіям з оголошеннями."
І нижче наводить приклад, який дуже схожий на принцип вектора Шеплі, про який поговоримо далі. Тут, на скріні, порівнюються ланцюжки з каналом Display та без нього:
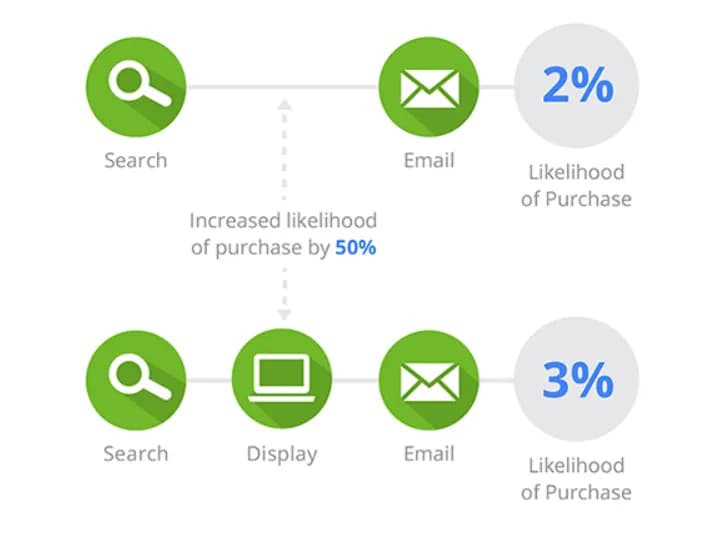
Цей приклад показує, що ланцюжки, в яких присутній канал Display, мали коефіцієнт конверсії 3%, а якщо його немає, то коефіцієнт був 2%. Таким чином, присутність каналу Display в ланцюжку підвищує ймовірність конверсії на 50%.
Про те, що GA4 використовує в своїй основі вектор Шеплі, можна судити на основі дедуктивної здогадки – в цій статті з довідки прямо вказується, що Google бере за основу вектор Шеплі, але з приміткою, що “ця функція доступна лише в Google Analytics 360”.

А якщо переключити на англомовну версію, то ми побачимо, що цей же підхід використовувався і в Universal Analytics. Я особисто сумніваюся, що в звичній Google Analytics використовується щось радикально інше за своїм принципом. Хіба що, можливо, покращену версію, яка не враховує в ланцюжках прямий трафік, про що свідчить приставка “non-direct” біля назв усіх моделей, які залишилися в GA4.

І це ми говоримо, що вектор Шеплі взятий “за основу”. Якщо даних недостатньо, то при порівнянні DDA та Last click (non-direct) відмінність буде малопомітна. Я зустрічала неофіційні твердження, що DDA в GA4 використовує вектор Шеплі “з домішками моделі на основі давності (Time-Decay)”, що мені виглядає логічно і прозаїчно: якщо даних недостатньо для машинного навчання, використовується менш “розумна” модель, для якої не важлива кількість даних, але вона все одно називається в інтерфейсі “data-driven”. Прошу вибачення за свій сарказм “на основі даних”.
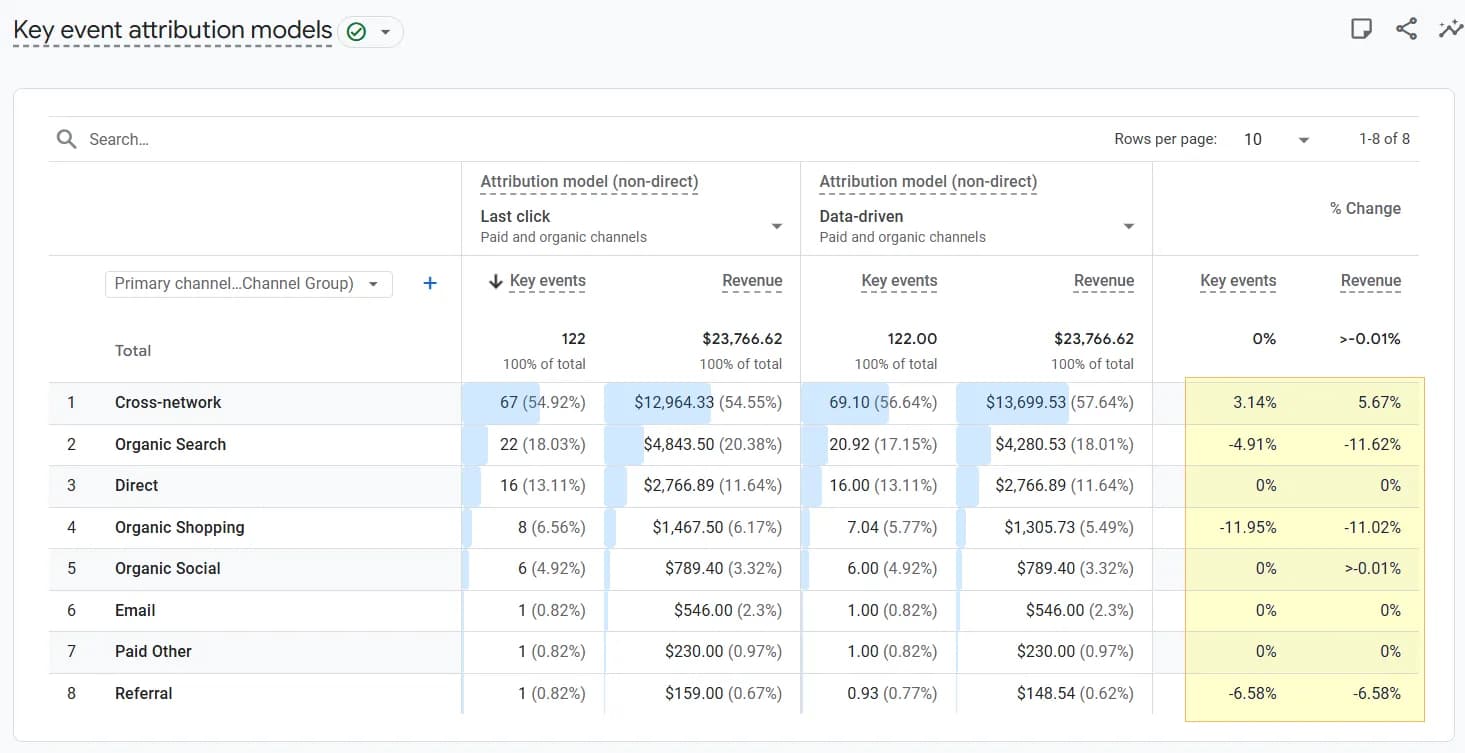
І зараз цілком справедливо задати питання: “а скільки ж треба даних, щоб їх було достатньо?”
Тут теж немає конкретної відповіді від Google. Якщо звернутися знову до легасі-статті, то в ній було чітко прописано: для data-driven потрібно щонайменше 400 подій конверсії, яку ви аналізуєте, за останні 28 днів. Для GA4 цю умову наче як спростили, але водночас поки (березень 2026) не надали опису, як усе працює зараз.
Резюмуючи: згідно з довідкою Universal Analytics, є велика вірогідність, що GA4 використовує за основу вектор Шеплі, але при цьому немає конкретики щодо вимог, яких потрібно дотримуватися, щоб модель була дійсно data-driven. Відповідно до загальних принципів машинного навчання, для будь-якої моделі даних повинно бути достатньо, щоб вона “зрозуміла” залежності в них і при цьому була менш упередженою, тобто допускала менше помилок. Тому є велика ймовірність, що якщо даних в GA4 не вистачає, то ви бачите в інтерфейсі під назвою “Data-driven” щось значно простіше і при цьому не здогадуєтеся про це.
Чи є це погано? На мою думку, так. Бо під виглядом моделі, яка “аналізує доступні дані про шляхи до ключових подій”, у рандомний момент ви можете отримати те, що цього, вірогідно, не робить. І це може призвести до переоцінки одних каналів у ланцюжку і недооцінки інших, і ви при цьому будете свято вірити, що ви зробили висновок “на основі справедливого розподілення внеску всіх каналів у ланцюжку”, чим характеризується вектор Шеплі, про який зараз і піде мова.
Принцип розрахунку вектора Шеплі
В попередньому розділі ми багато говорили, що з великою долею вірогідності ця модель використовується як основа для DDA в GA4. Тепер давайте розберемося з логікою, яка в неї закладена.
Основна складність моделей машинного навчання полягає в тому, що пояснити їх простою мовою іноді непросто, але я спробую :)
Далі я буду максимально все спрощувати і робити доступним для сприйняття. Я опускаю багато нюансів і не наводжу складні формули, при цьому намагаюся повноцінно донести саме суть логіки, що більш важливо в контексті статті.
Уявімо, що у нас є такий набір ланцюжків до конверсії, де A, B і C – джерела трафіку на сайт:
B = 1 конверсія
A → C = 2 конверсії
B → C → A = 1 конверсія
Всього: 5 конверсій
Для Шеплі кожен із каналів – це гравець, який кооперується з іншими в команду для досягнення виграшу, себто конверсії.
За замовчуванням порядок “гравців” ігнорується, тобто останній ланцюжок
- Формування коаліцій
Отримавши дані, модель виокремлює список унікальних каналів і створює з нього “коаліції”, тобто комбінації каналів та загальну суму конверсій для кожної. Якщо у комбінації немає конверсій, Шеплі вважає, що ця комбінація неконверсійна. Таким чином отримуємо наступне:
| Коаліція і цінність | Пояснення |
|---|---|
v(∅) = 0 | стартова позиція – відсутність каналів |
v(A) = 1 | з A у нас є один ланцюжок і 1 конверсія з нього |
v(B) = 1 | аналогічно тільки з B у нас є один ланцюжок і 1 конверсія з нього |
v(C) = 0 | немає ланцюжків, де був би тільки канал C, тому ця коаліція має 0 конверсій. |
v(A,B) = 2 | коаліція каналів (A,B) вміщує 2 шляхи: тільки A та тільки B, тому їхня спільна цінність – сума їхніх конверсій: 1(A) + 1(B) |
v(A,C) = 3 | коаліція (A,C) може “ходити” двома шляхами: ланцюжок А (1 конверсія) та A → C (2 конверсії). Разом 1(A) + 2(A,C) = 3 |
v(B,C) = 1 | коаліція (B,C) може виконати тільки один ланцюжок B (1 конверсія). Ланцюжок A → C не під силу, бо немає А. |
v(A,B,C) = 5 | Це "гранд-коаліція". Вона включає всі канали, тому сюди плюсуються абсолютно всі конверсії: 1(A) + 1(B) + 2(AC) + 1(BCA) |
2. Оцінка внеску канала в комбінації з іншими
Після цього модель формує всі можливі комбінації порядку каналів:
A → C → B
B → A → C
B → C → A
C → A → B
C → B → A
Та для кожної рахує внесок каналу (скільки він додає) при приєднанні до різних “команд”:
Розглянемо як це відбувається на прикладі першого порядку A → B → C:
| Внесок | Розрахунок | Пояснення |
|---|---|---|
A | v(A) - v(∅) = 1 - 0 = 1 | Завжди стартуємо з відсутності каналів – v(∅)=0. При появі сам по собі канал A додає 1 конверсію. |
B | v(A,B) - v(A) = 2 - 1 = 1 | При додаванні каналу B ми маємо відняти цінність A від коаліції (A,B), таким чином B додав від себе в цьому порядку 1 конверсію. |
C | v(A,B,C) - v(A,B) = 5 - 2 = 3 | Тепер додаємо C і розраховуємо його вклад як цінність всієї коаліції (A,B,C) мінус цінність (A,B), тобто C в цьому випадку додав 3 конверсії. |
Таким чином модель розраховує внесок кожного каналу у всіх комбінаціях і отримує такий результат:
| Порядок | Внесок A | Внесок B | Внесок C |
|---|---|---|---|
A → B → C | 1 | 1 | 3 |
A → C → B | 1 | 2 | 2 |
B → A → C | 1 | 1 | 3 |
B → C → A | 4 | 1 | 0 |
C → A → B | 3 | 2 | 0 |
C → B → A | 4 | 1 | 0 |
Якщо вам стало цікаво, чому інколи C має суттєву долю, а інколи – нульову, розберемо ще один кейс, де C = 0: B → C → A
| Внесок | Розрахунок | Пояснення |
|---|---|---|
B | v(B) - v(∅) = 1 - 0 = 1 | При появі канал B додає 1 конверсію, як і в попередньому кейсі. |
C | v(B,C) - v(B) = 1 - 1 = 0 | Щоб визначити вклад C ми віднімаємо цінність B від коаліції (B,C). І фактично C в цьому випадку нічого не додав. І це логічно, бо цінність всієї коаліції (B,C) складається з B – немає ланцюжків C або B → C. |
A | v(A,B,C) - v(B,C) = 5 - 1 = 4 | Додаємо A і розраховуємо його вклад як цінність всієї коаліції (A,B,C) мінус цінність (B,C). “Прийшовши в команду”, A розблокував конверсії по шляхам A, A → C та B → C → A. |
Фінальний розрахунок середнього внеску каналу
Залишилось порахувати середній внесок кожного каналу по всіх комбінаціях:
Канал B: (1+2+1+1+2+1)/6 = 8/6 = 1.333… конверсії
Канал C: (3+2+3+0+0+0)/6 = 8/6 = 1.333… конверсії
І у відсотковому розподіленні:
Канал B: 1.333 / 5 ≈ 26,7%
Канал C: 1.333 / 5 ≈ 26,7%
Якщо порівняти ці результати з класичною rule-based моделлю “останній непрямий клік”, то ми побачимо таке:
Канал B: 1 конверсія (20%)
Канал C: 2 конверсії (40%)
Шеплі нам допоміг зрозуміти, що C добре працює в парі з A, і його заслуга насправді менша, аніж 2 конверсії. В цьому і “справедливість” розрахунку внеску каналу – C не настільки цінний канал, як ми б побачили по моделі last non-direct.
Канал B насправді ж мав більше однієї конверсії, бо він брав участь у досягненні ще однієї в коаліції з іншими.
Канал A при цьому має найбільшу цінність – Шеплі підкреслює, що він зустрічається у більшості конверсійних випадків, тому цінність у цього каналу найвища – без нього конверсій було б значно менше, вважає Шеплі.
З попереднього прикладу можна винести ще одне спостереження: чим частіше канал зустрічається в конверсійних ланцюжках, тим більший його “вклад у спільну справу”. А тепер проведіть мисленнєвий експеримент та уявіть, що A – це (direct) / (none)...
Прямий трафік нерідко займає одне з топових місць серед каналів трафіку і тому може доволі суттєво “перетягувати на себе ковдру” в такому розрахунку. Але ця інформація сама по собі несе мало цінності – ми не можемо цілеспрямовано масштабувати цей канал. Я думаю, саме така логіка була у Google, коли він вирішив виключити direct з моделей, про що свідчить приставка “(non-direct)” біля назв моделей в інтерфейсі на попередньому скріншоті.
Про інші особливості, які треба взяти до уваги, коли ви будете розраховувати таку атрибуцію самостійно, ми поговоримо далі.
Цікава особливість Шеплі
Ви колись бачили в аналітичній системі щось подібне:
Так, мінус 1.2 конверсії
Думаю, навряд. А шкода…
Хоча я розумію, чому системи не показують нам від’ємних конверсій – це б виносило мозок. Нам непросто усвідомити дробові конверсії, як-от 1.2 штуки, не те, що facebook нам “приніс мінус 1.2 конверсії”. Проте така картина була б максимально наближеною до внеску каналу згідно з Шеплі, який вміє “карати” канал за його негативний внесок у коаліції.
Шеплі не про те, скільки приносить канал, а про те, наскільки змінюється цінність, коли канал з’являється в конкретному контексті.
Приведу приклад:
A → C = 1 конверсія
Тоді:
v({A,C}) = 1
В ситуації, коли C додається після A, тоді внесок
Це може означати наступне:
- користувачі, які побачили C, гірше конвертувались, ніж ті, хто бачив лише A.
- C канібалізує ефект A.
- або C створює зайвий крок, відволікає.
Ще трохи прикладів, вже наближених до непростого маркетингового життя:
- Зайвий Email
Search = 8 конверсій
Search → Email = 5 конверсій
Внесок Email = -3
Email тут не прогрів / не додав цінності / просто затримав на шляху до покупки. - Ремаркетинг, який шкодить бренду
Brand Search = 12 конверсій
Brand Search → Remarketing = 9 конверсій
Внесок Remarketing = -3
Ремаркетинг нав’язливо переслідує / знижує довіру до бренду. - Конфлікт повідомлень
Email (знижка) = 6 конверсій
Email (знижка) → Display (без знижки) = 3 конверсії
Внесок Display = -3
Display збиває іншим меседжем / знімає “терміновість” знижки.
Тут є важливий нюанс – Шеплі карає не за присутність, а за шкоду.
Від’ємний внесок виникає, коли шлях із каналом конвертує гірше, ніж схожий шлях без нього. Канал може бути хорошим солдатом, але поганим сусідом. Шеплі якраз і показує, з ким і коли його краще не ставити поруч.
Так чому ми не бачимо від’ємні цифри в GA4, якщо за основу він використовує вектор Шеплі? Я здогадуюсь, що справа в обробці, яка обнуляє мінусові цифри і змінює решту коефіцієнтів відповідно до внеску. Але це тільки моя здогадка, бо я не бачила скрипти “під капотом” GA4.
Водночас вектор Шеплі – це не державна таємниця. За наявності потрібних знань або людей цю модель можна застосувати до ваших даних і побачити реальний внесок, навіть мінусовий. Головне потім його правильно трактувати :)
Принцип ланцюга Маркова
Модель Шеплі не єдина, яку можна застосувати для маркетингової атрибуції за принципом data-driven. Ще однією популярною є ланцюг Маркова, підхід якого ми зараз і розглянемо.
Якщо порівняти ці моделі в двох словах, то вектор Шеплі – це “справедливий суддя”, який ділить виграш між гравцями, а ланцюг Маркова — це “картограф”, який малює всі можливі маршрути користувачів і рахує ймовірність переходу з однієї точки в іншу і відповідає на питання:
“Як зміниться кількість конверсій, якщо прибрати канал зі шляху?”
Це модель визначення впливу через видалення каналу (removal-effect), а не через справедливий поділ.
Ще однією відмінністю Маркова є важливість порядку каналів у ланцюжку – модель Маркова враховує порядок каналів:
Розберемо принцип детально на спрощеному наборі ланцюжків.
Звертаю вашу увагу, що набір інший, ніж для Шеплі.
Чому? У випадку з Шеплі мені було важливо показати, що порядок каналів не має значення. Якщо я візьму той же набір, то мені потрібно буде розповісти про цикли і як модель їх обробляє. Циклом з попереднього прикладу є ланцюжок
До набору даних про кількість сесій з мінімум 1 конверсією додамо ще кількість сесій, під час яких з відповідного ланцюжка конверсій не було:
| Ланцюжок | Конверсійні сесії (далі: CONV) | Сесії без конверсій (далі: DROP) | Всього сесій |
|---|---|---|---|
A | 2 | 18 | 20 |
B | 1 | 19 | 20 |
A → C | 4 | 16 | 20 |
B → C | 3 | 17 | 20 |
Якщо ви не надасте дані про неконверсійні шляхи моделі Шеплі, вона може побудувати подібне самостійно, перемножуючи між собою канали та додаючи 0, якщо немає даних по певній комбінації. Для моделі Маркова важливо знати не тільки, скільки разів ланцюжок сконвертувався, а й скільки разів він завершився нічим. Без цього модель буде думати, що всі рано чи пізно сконвертуються.
- Побудова матриці переходів
Для наглядності розкладемо наші дані візуально.

Ні, це ще не матриця переходів. Це мій творчий порив, чому б ні…
Тепер збираємо це в табличку наступним чином:
- На перехресті from START to A рахуємо суму чисел на відповідних стрілках START → A. Таких 2, тому 20 + 20 = 40 пишемо у відповідну клітинку.

2. На перехресті from START to B рахуємо суму чисел на відповідних стрілках START → B. Таких теж 2, тому 20 + 20 = 40 пишемо у відповідну клітинку.

3. На перехресті from START to C у нас нічого немає з START → C, тому пишемо 0.
4. І так далі…
В кінці рахуємо суму по рядках і отримуємо таке:
| From \ To | A | B | C | CONV | DROP | TOTAL |
|---|---|---|---|---|---|---|
START | 40 | 40 | 0 | 0 | 0 | 80 |
A | 0 | 0 | 20 | 2 | 18 | 40 |
B | 0 | 0 | 20 | 1 | 19 | 40 |
C | 0 | 0 | 0 | 7 | 33 | 40 |
Тепер рахуємо ймовірність переходу простим діленням значення в клітинці на тотал по рядку. Вже тут отримуємо матрицю ймовірності переходів:
| From \ To | A | B | C | CONV | DROP | TOTAL |
|---|---|---|---|---|---|---|
START | 0.5 | 0.5 | 0 | 0 | 0 | 1 |
A | 0 | 0 | 0.5 | 0.05 | 0.45 | 1 |
B | 0 | 0 | 0.5 | 0.025 | 0.475 | 1 |
C | 0 | 0 | 0 | 0.175 | 0.825 | 1 |
2. Рахуємо baseline конверсії та removal effect.
Baseline рахується доволі складно і повинен врахувати всі шляхи, в т.ч. зацикленість, наприклад шлях
На розуміння принципу моделі це спрощення не вплине, але нюанс, який ви маєте знати: оскільки реальні дані часто значно складніші за наш приклад, ймовірність конверсії може дещо відрізнятися від простого коефіцієнту.
Для наглядності зведемо матрицю візуально:

Тепер по цій карті перерахуємо всі можливі шляхи, по яким ми можемо дістатись з START до CONV, та перемножимо ймовірності, щоб дізнатись можливу конверсію кожного шляху:
| # | Можливий шлях | Ймовірність конверсії | Результат множення |
|---|---|---|---|
1 | START → A → CONV | 0.5 * 0.05 | 0.025 |
2 | START → A → C → CONV | 0.5 * 0.5 * 0.175 | 0.04375 |
3 | START → B → C → CONV | 0.5 * 0.5 * 0.175 | 0.04375 |
4 | START → B → CONV | 0.5 * 0.025 | 0.0125 |
Сума | 0.125 |
Сума результатів дорівнює коефіцієнту конверсії – це проста перевірка, що ми йдемо правильним шляхом.
Тепер по черзі прибираємо канали з матриці і перераховуємо, якою буде конверсія без нього.
Прибираємо A і втрачаємо можливість “йти” шляхами 1 і 2. Тепер зі старту можна піти тільки в B, тому START → B буде 1 або 100%.

Оновлюємо дані в таблиці і перераховуємо можливу конверсію:
| # | Можливий шлях | Ймовірність конверсії | Результат множення |
|---|---|---|---|
3 | START → B → C → CONV | 1 * 0.5 * 0.175 | 0.0875 |
4 | START → B → CONV | 1 * 0.025 | 0.025 |
Сума | 0.1125 |
Ймовірність конверсії без A = 0.1125, що відрізняється від baseline на (0.125 - 0.1125) / 0.125 = 0.1
або 10% – це і є removal effect.
Можна трактувати це так, що ми можемо втратити 10% конверсій, якщо приберемо канал A.
Тепер аналогічно порахуємо removal effect для решти каналів:
Ймовірність конверсії без B: 1 * 0.05 + 1 * 0.5 * 0.175 = 0.1375
Removal effect для B: (0.125 − 0.1375) / 0.125 = -0.1 або −10%
Ми можемо втратити мінус 10% конверсій, якщо приберемо канал B… Йой… Тобто є ймовірність, що B знижує конверсію на 10%!
Так, Марков, як і Шеплі, теж може “викривати невдах”.
Ймовірність конверсії без C – це сума ймовірностей шляхів 1 та 4: 0.5 * 0.05 + 0.5 * 0.025 = 0.0375
Removal effect для C: (0.125 − 0.0375) / 0.125 = 0.7 або 70%
Без C ми можемо недоотримати 70% конверсій.
Підсумок ефекту видалення:
B = −10%
C = 70%
Обнуляємо негатив та нормалізуємо решту для консистентності:
B = 0
C = 70 / 80
Отримуємо розподілення долі конверсій по каналах згідно Маркову:
B = 0%
C = 87.5% або 10 * 0.875 = 8.75 конверсій
Ви ще зі мною? Нічого собі…

Що потрібно врахувати “на березі”
Тоді давайте поговоримо про особливості цих data-driven моделей.
Гранулярність
Обидві моделі чутливі до кількості унікальних каналів. Чим їх більше, тим більша вірогідність побачити скошений вплив.
Наприклад, розглянемо такі ланцюжки:
- Тільки канали трафіку:
- cpc →
- organic →
- organic →
- cpc
Кількість унікальних каналів = 2: cpc та organic
- Додаємо джерела:
- google / cpc →
- google / organic →
- google / organic →
- google / cpc
Кількість унікальних каналів все ще = 2: google / cpc та google / organic
- Додамо кампанії:
- google / cpc / search →
- google / organic / (organic) →
- google / organic / (organic) →
- google / cpc / brand
Кількість унікальних каналів вже = 3: google / cpc / search, google / cpc / brand та google / organic
Як ви вважаєте, що буде більш важливим каналом для обох моделей – 2 торкання google / organic чи по одному з рекламних кампаній?
Правильно, вплив google / organic буде більшим.
За логікою моделей, безсоромно спрощеною до нанометра, чим частіше унікальний канал бере участь в конверсійних ланцюжках, тим вища його цінність. Тому якщо 30% конверсій прийшло з органіки, а 70% – з Google Ads, і ви захочете змоделювати вплив кожного оголошення, будьте готові побачити, що нічого, окрім брендових, не має значення, тому що весь вплив буде розподілений між оголошеннями на молекули, щоб “дісталося кожному”. Ну а на першому місці буде органіка, звісно.
Якщо ви хочете бачити щось трохи детальніше, ніж джерело / канал, наприклад, рекламні кампанії, додавайте хоча б посадкові сторінки до органічних каналів, щоб зрівняти розбивку. І точно не раджу оброблювати дані, розбиті ще більше – до ключових слів та / або оголошень.
Врахування порядку
Ви, напевно, пам’ятаєте, що Шеплі ігнорує його, а Марков враховує.
Але при цьому у нього “коротка пам’ять” – на ймовірність перейти на наступний крок впливає тільки те, на якому кроці ви знаходитесь зараз, але не те, що було перед цим. На прикладі з попереднього розділу конверсія з каналу C буде 0.175 незалежно від того, яким був канал перед ним – A чи B. При цьому якщо уявити, що канал C – це ремаркетинг, A – брендовий трафік, а B – реклама на холодну аудиторію в Meta, то інтуїтивно ймовірність конверсії з ремаркетингу після брендової кампанії вища, ніж після холодного трафіку. Але модель Маркова цього не “бачить” – вона присвоює C однакову ймовірність конверсії в обох випадках.
Тому якщо ви очікуєте, що Марков зможе показати чітку послідовність дотиків, яку вам краще вибудувати зі своєю аудиторією, то, на жаль, він цього зробити не зможе.
Кількість джерел у послідовності
Це про середню довжину ланцюжка до конверсії. Шеплі краще застосовувати до коротших ланцюжків, де в середньому до 5–8 унікальних каналів.
Якщо зазвичай ваш клієнт проходить тривалий шлях до конверсії з багатьма дотиками, Шеплі не дозволить вам побачити реальний вплив каналів, які зустрічаються відносно рідко. Модель, вірогідно, “покарає” їх і призначить негативний вплив.
Марков в цьому плані краще може виявляти канали, які рідко закривають, але є ключовими на шляху до конверсії, і без них система може посипатися.
Розподілення між каналами
Якщо у вас умовно є топ каналів, які дають основний трафік і конверсії, і різниця між ними значуща, як в одному з прикладів – 70% реклама і 30% органіка, то data-driven атрибуція, скоріш за все, вам нічого нового не розкаже. Ці моделі можуть допомогти вам зрозуміти, який вплив мають певні канали, якщо ви не знаєте, хто з них працює краще, бо їхня ефективність приблизно однакова.
Порівняння особливостей
Підсумуємо все, що ми дізналися про 2 data-driven моделі, в резюмуючій таблиці:
| Особливість | Вектор Шеплі | Ланцюг Маркова |
|---|---|---|
Базова ідея | Ділить “цінність” конверсії між каналами. | Міряє, що зламається, якщо канал прибрати. |
Логіка оцінки | Оцінює внесок каналу при приєднанні до різних «команд» (коаліцій). | Ефект видалення (removal-effect): що станеться, якщо прибрати канал. |
Врахування порядку | Ігнорує порядок; важливий лише факт присутності каналу в ланцюжку. | Враховує порядок каналів у послідовності, але має "коротку пам'ять". |
Дані про відмови | Може побудувати модель навіть без даних про неконверсійні шляхи. | Обов'язково потребує дані про сесії без конверсій (drop). |
Довжина ланцюжка | Найкраще працює з короткими шляхами (5–8 унікальних каналів). | Ефективніший для складних і довгих шляхів до конверсії. |
Виявлення негативу | Вміє ”карати” канали за негативний внесок (канібалізацію). | Також викриває канали, видалення яких може покращити конверсію. |
Підходить для оптимізації бюджету | Якщо важлива “справедливість” | Якщо важлива структура шляху. |
Інтерпретація для бізнесу | “Хто скільки заслужив” | “Хто критичний для системи” |
Коротше кажучи:
- Вектор Шеплі ідеальний для проєктів із коротким циклом прийняття рішення, де важливо справедливо розподілити цінність між кількома каналами.
- Ланцюг Маркова краще підходить для складного маркетингу, оскільки дозволяє побачити канали-“мости”, які самі не закривають конверсію, але без яких шлях користувача обірветься.
Заключна думка
Жодна з моделей атрибуції не є “правильною” і не дасть кінцевої відповіді на питання “що працює, а що ні?”
До будь-якої моделі треба ставитися не як до істини в останній інстанції, а як до кута, під яким можна поглянути на дані.
Моя проста порада – не обмежуйтеся поглядом тільки під одним кутом зору, бо тоді ви можете пропустити щось важливе. Якщо вам будуть доступні декілька граней ваших даних, ви зможете вловити з них більше інсайтів.
Навіть якщо ви прийдете до одних і тих самих висновків на основі різних моделей атрибуції – це теж цінний інсайт: можна сказати, що моделі згодні з висновками одна одної і підтверджують їх.
Цінне і зворотне – якщо в розрізі різних моделей ви спостерігаєте різну поведінку каналів – це прекрасна підказка, що вам треба заглибитися більше і дослідити причини, чому так відбувається.
А ще я сподіваюся, що я змогла вам показати, що з data-driven підходом краще бути обережним. Щоб результати не ввели вас в оману, треба враховувати їхні особливості. Врешті, ніхто не відміняв класичний rule-based підхід – він може бути не настільки “розумним”, але може стати хорошим і простим для розуміння доповненням до data-driven.
Коментарі
Поділися думкою та постав запитання
Завантаження коментарів...