

Євгенія Ярушина
Тимлід аналітичної командиЕкспорт даних GA4 у BigQuery через серверний тег менеджер: покроковий гайд з налаштування
Трошки передісторії. Усім нашим клієнтам ми радимо налаштовувати експорт даних з GA4 до BigQuery. Навіщо це треба? Якщо коротко - щоб проводити більш глибокі дослідження даних GA4 та легко поєднувати їх з даними інших систем в наскрізні звіти. Якщо цікавить більш розгорнутий варіант - ознайомтесь зі статтею мого колеги - Все, що треба знати про BigQuery: що це, навіщо та які переваги для маркетингу.
Але повернемось до теми мого матеріалу. На одному з наших проєктів був налаштований щоденний експорт даних з GA4 до BigQuery. Але в певний момент, ми почали перевищувати ліміти в 1 мільйон подій на день і, як наслідок, щоденний експорт став недоступним.
Звісно, існує опція підключення Analytics 360, де можна отримати щоденний експорт з більшими лімітами, але клієнт не був готовий до таких витрат, тому вирішили пошукати інше рішення.
Перша ідея - використовувати "рідний" стрімінг GA4 до BigQuery. Але в цьому варіанті ми зіштовхнулись з великою втратою даних, про яку я розповім детальніше. Тому, власне, й почали проводити дослідження стосовно цієї проблеми та шукати рішення, як би нам отримувати всі дані.
Недоліки експорту даних з GA4 у BigQuery
Згідно того, що пише Google в офіційних довідках, у щоденному оновленні розбіжність у даних між інтерфейсом GA4 та BigQuery може бути близько +-2-5%, а для стрімінгу Google взагалі не дає жодних відсотків, лише надає незрозуміле пояснення.

Тобто немає жодних точних цифр стосовно повноти даних. Багато користувачів пишуть про великі розбіжності.
Щодо нашого досвіду, на реальному проєкті втрати сягали близько 10-20 %. Інколи вдавалось спіймати відвал в розмірі 70-80% по кастомній події створення замовлення відносно інтерфейсу GA4. Нижче на скріні реальні значення по декількох івентах.
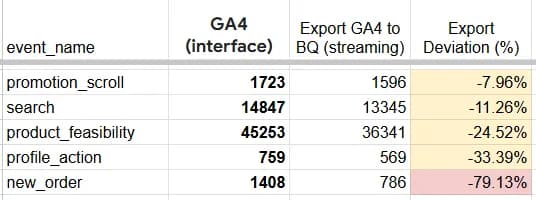
- event_name - назва події з GA4
- GA4 (interface) - кількість подій в інтерфейсі GA4
- Export GA4 to BQ (streaming) - кількість подій в BigQuery з експорту GA4 (streaming)
- Export Deviation (%) - відсоток втрат у експорті, порівняно з інтерфейсом
З такими відхиленнями неможливо працювати, тому потрібно було шукати інший варіант, щоб отримувати всі дані. Спосіб, на якому ми вирішили зупинитись - передача даних GA4 з Server-Side GTM напряму в BigQuery. Враховуючи, що серверний тег-менеджер вже використовувався на проєкті задача не виглядала складною. У Simo Ahava є чудова стаття, де він описує цей спосіб і ми також знайшли декілька готових шаблонів в серверному GTM, які вже були створені під таку задачу. Про їхні особливості, та чому ми вирішили розробити своє рішення, детальніше поговоримо в наступному пункті.
Фіналізуємо: якщо у вас також налаштований стрімінг і ви зіштовхнулись з великими втратами, то варіант передачі даних, який я описую в цьому матеріалі однозначно стане вам в нагоді.
На цьому етапі у мене був ступор стосовно плавного підведення до плану статті, тому просто розміщу його нижче, щоб не мучити ні себе, ні вас)
Доступні рішення в Server-Side GTM та їхні особливості
Коли шукаєш рішення якоїсь задачі, то завжди спочатку перевіряєш, “чи не робив це вже хтось до тебе?”. В даному випадку ми теж пішли по шляху меншого опору і дослідили наявні готові шаблони в серверному GTM для запису даних в BigQuery.
Перед тим, як почати пошуки, потрібно було визначитись з бажаним результатом.
Що саме ми хотіли отримати?
- Усі дані, що відправляються в GA4 з Server-Side GTM записуються в BigQuery без втрат
- Отримати ці дані у структурі, наближеній до схеми експорту GA4.
- Налаштувати в фінальній таблиці партиціювання по даті та кластеризацію по назві події для оптимізації як швидкості виконання запитів так і витрат.
- Шаблон від OWOX - Google Analytics 4 RawData to BigQuery
- До коректності роботи цього шаблону питань немає - всі дані потрапляють в BigQuery, але потрапляють вони у дійсно “сирому” вигляді. За замовчуванням, в цьому шаблоні є лише два поля, що запишуться в таблицю:
createdAt - таймстемп події - rawDataOwox - усі дані, що відправляються в GA4, включно з системними параметрами та даними єкому в одному полі
Нижче на скріні приклад, як саме будуть виглядати ці дані в полі rawDataOwox

Напевно, ви вже зрозуміли, чому нам цей варіант не підійшов - працювати з такими даними незручно. І в таблиці відсутнє партиціювання та кластеризація.
Ми прагнули створити більш зручне рішення, яке дозволило б ефективніше працювати з даними. До того ж, використання партиціювання та кластеризації дає змогу оптимізувати обробку запитів у BigQuery. А це особливо важливо для роботи з великим обсягом даних. Такі налаштування дозволяють зменшити навантаження на систему та підвищити швидкість отримання результатів. І не забувайте про те, що це економить кошти на обробку запитів. Але поточний шаблон не передбачає подібних налаштувань.
2. Шаблон від taneli-salonen1 - BigQuery Event
Цей варіант вже видався цікавішим - в тезі було більше полів, які записувались в таблицю окремо:
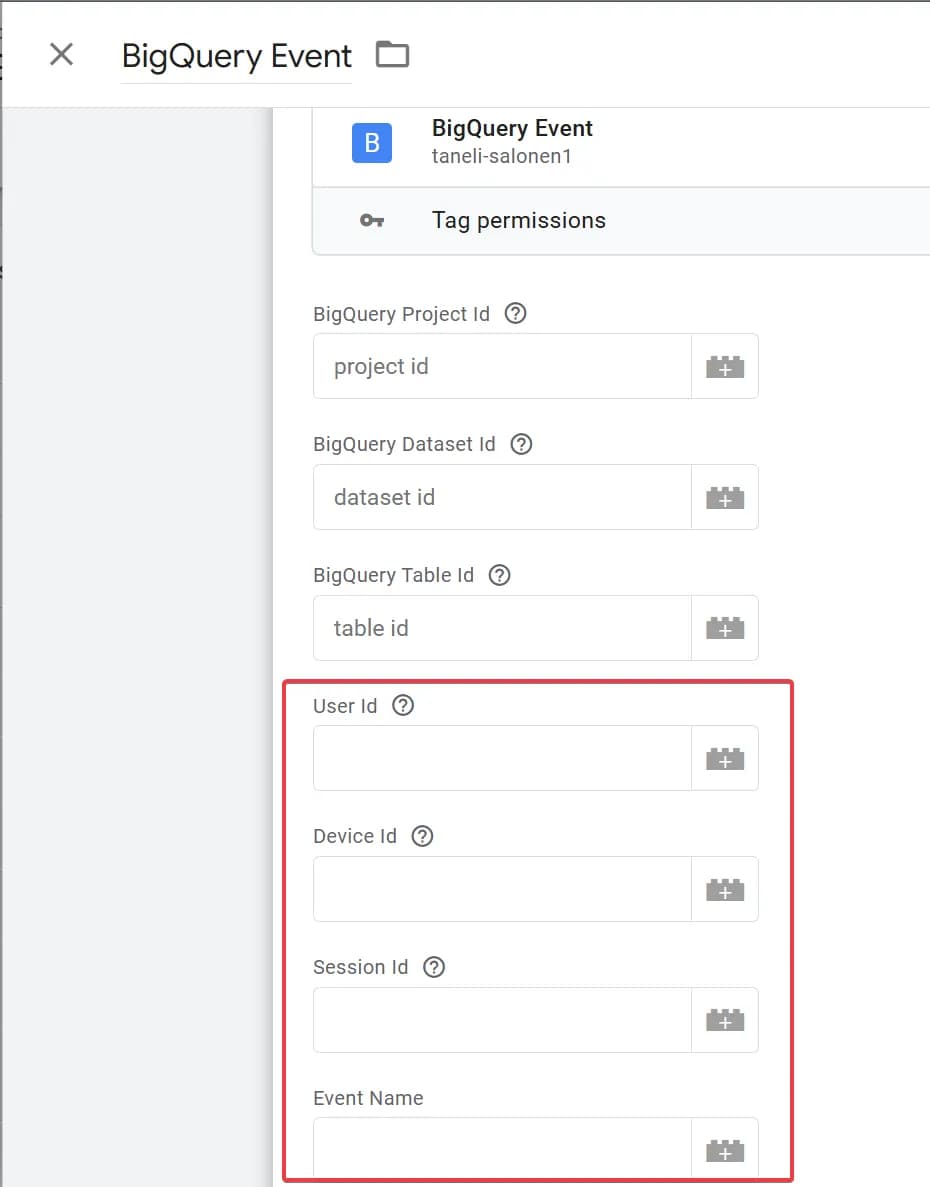
Це вже дало б змогу налаштувати кластеризацію за event_name для економії, але все ще не те, що нам було потрібно.
Дані частково записувались в окремі поля (саме ті, що виділила червоним на скріні + event_timestamp), а усе інше - летіло в event_params. Вже краще, детальніше, але все ще не те.
На цьому етапі ми в команді прийшли до висновку, що якщо хтось інший може створити шаблон тега в Server-Side GTM, то чому ми цього не можемо зробити? І тут почалось найцікавіше.
Створення власного шаблону GA4 Data Export to BigQuery та його використання
Нам потрібно було створити шаблон, який буде коректно опрацьовувати та записувати дані в потрібні поля в потрібному форматі.
Звісно, що це процес не одного дня, і ми провели багато тестів, поки не реалізували ці 3 пункти, описані вище в тому вигляді, в якому це нас влаштовувало.
У мене немає знань написання коду на JavaScript на рівні професійного розробника, але мого рівня знань як для веб-аналітика виявилось цілком достатньо. Все що було потрібно - розуміти базові принципи JS. Часом я також використовувала ChatGPT для економії часу. Тому не лякайтесь, коли прогорнете трохи далі і побачите багато коду: для розуміння описаного рішення та внесення змін вам не потрібно бути розробником. Я спробую максимально детально описати процеси, які в ньому відбуваються.
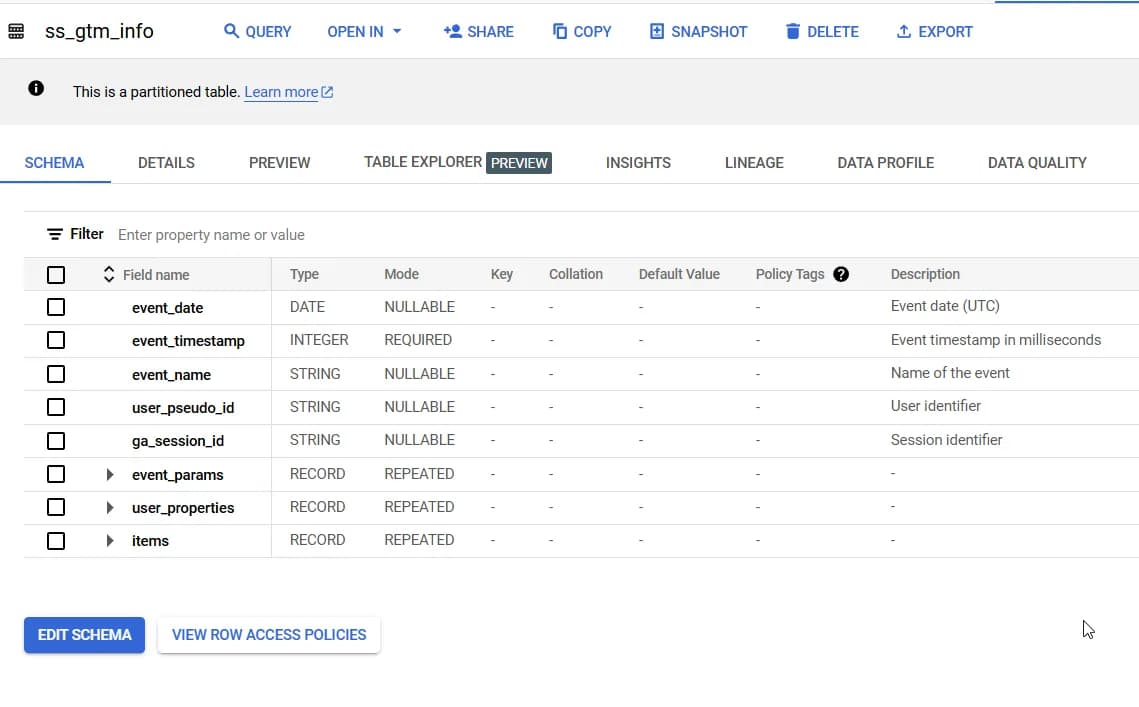
Перш ніж ми перейдемо до найцікавішого, покажу результат, який ви отримаєте в фіналі у вигляді схеми даних таблиці в BigQuery:
Для порівняння додам скрін зі схемою експорту з GA4, де жовтим виділила дані, що відокремлені в нашій структурі:
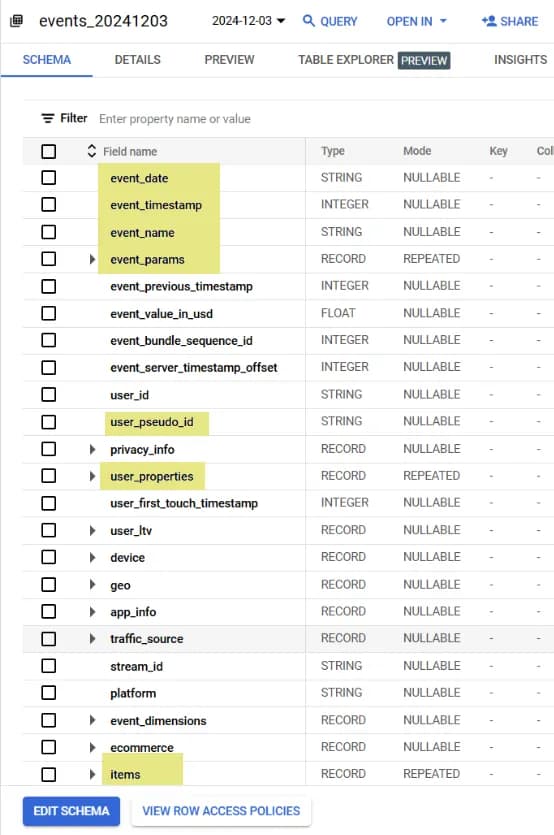
Зрозуміло, що наша таблиця не відтворює ВСІ поля з експорту GA4, але частину з основними полями, параметрами на рівні події, даними про товари та властивостями користувача закриває.
В поточній структурі з шаблону ви отримаєте:
- event_date
- event_timestamp
- event_name
- user_pseudo_id
- ga_session_id
- event_params
- user_properties
- items
Знову ж таки, ми не пропонуємо наш шаблон як точний замінник для передачі даних з GA4 в такому ж форматі - ми використали саме таку структуру, бо вона підходила для закриття наших потреб.
Тому мета цієї статті, з однієї сторони, презентувати наше рішення, а з іншої - пояснити детально як все влаштовано, щоб ви могли адаптувати рішення під себе та деталізувати структуру таблиці.
Рішення, яке я описую ще не додано в галерею шаблонів, тому щоб використати шаблон зробіть наступне:
- Завантажуємо шаблон з GitHub (клікаємо на іконку для завантаження)
2. Заходимо в серверний GTM
3. В розділі Templates клікаємо на кнопку New, імпортуємо збережений шаблон та зберігаємо
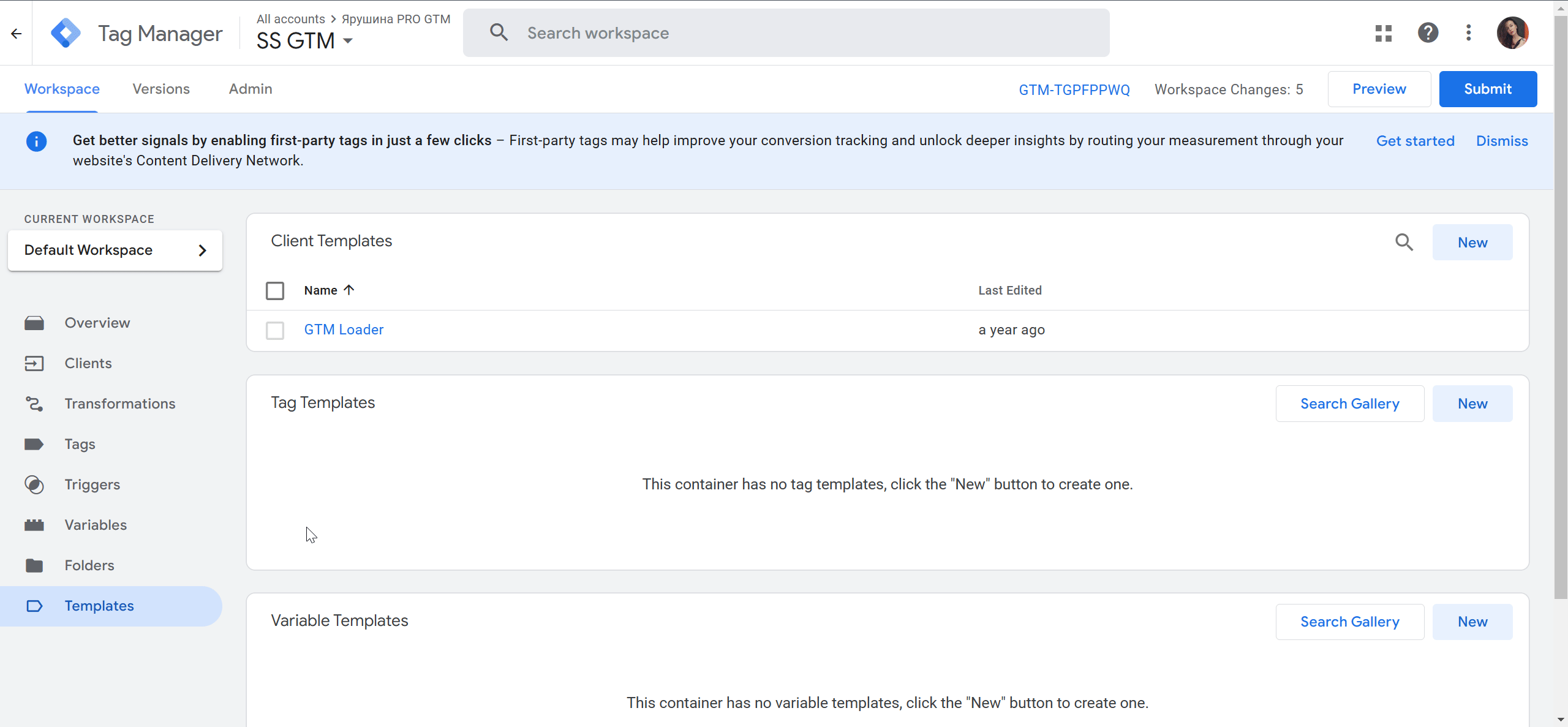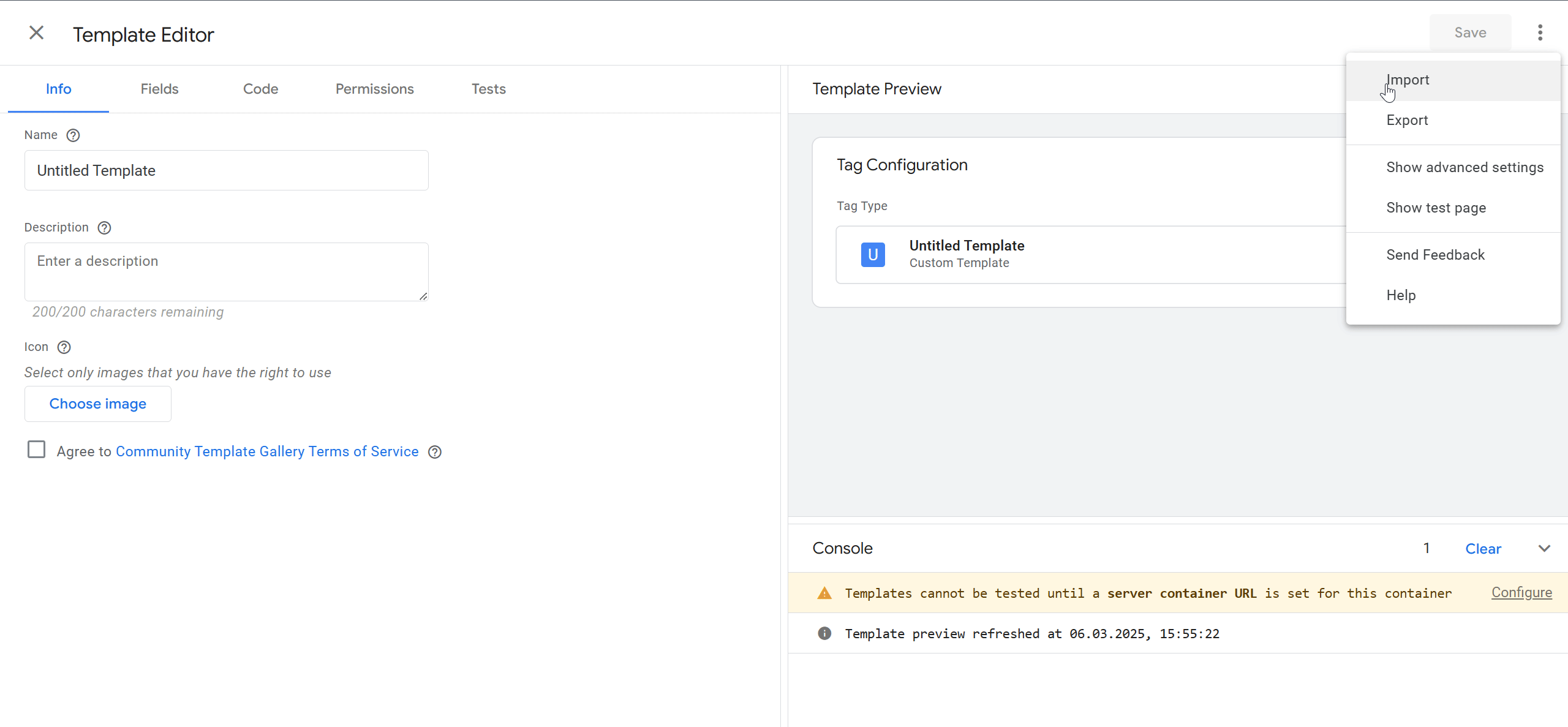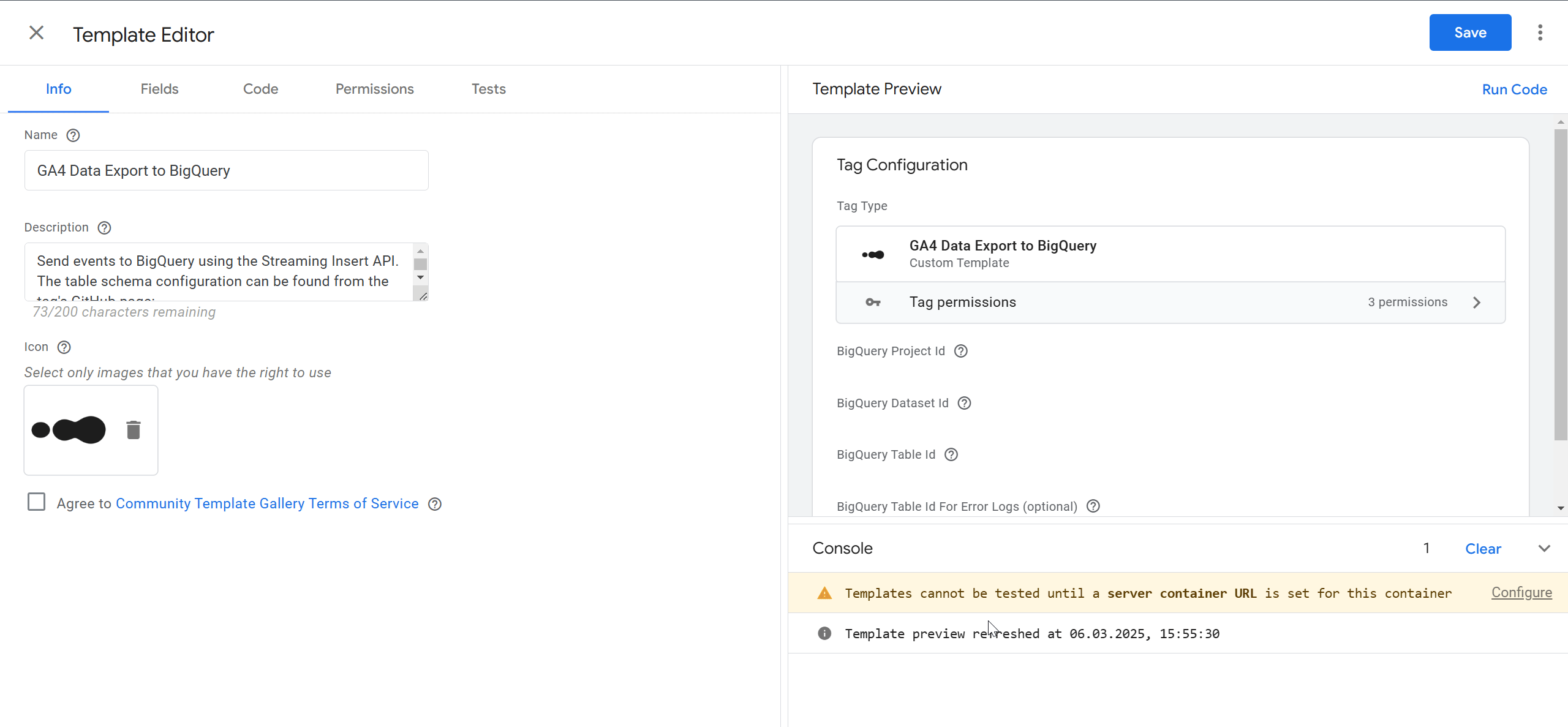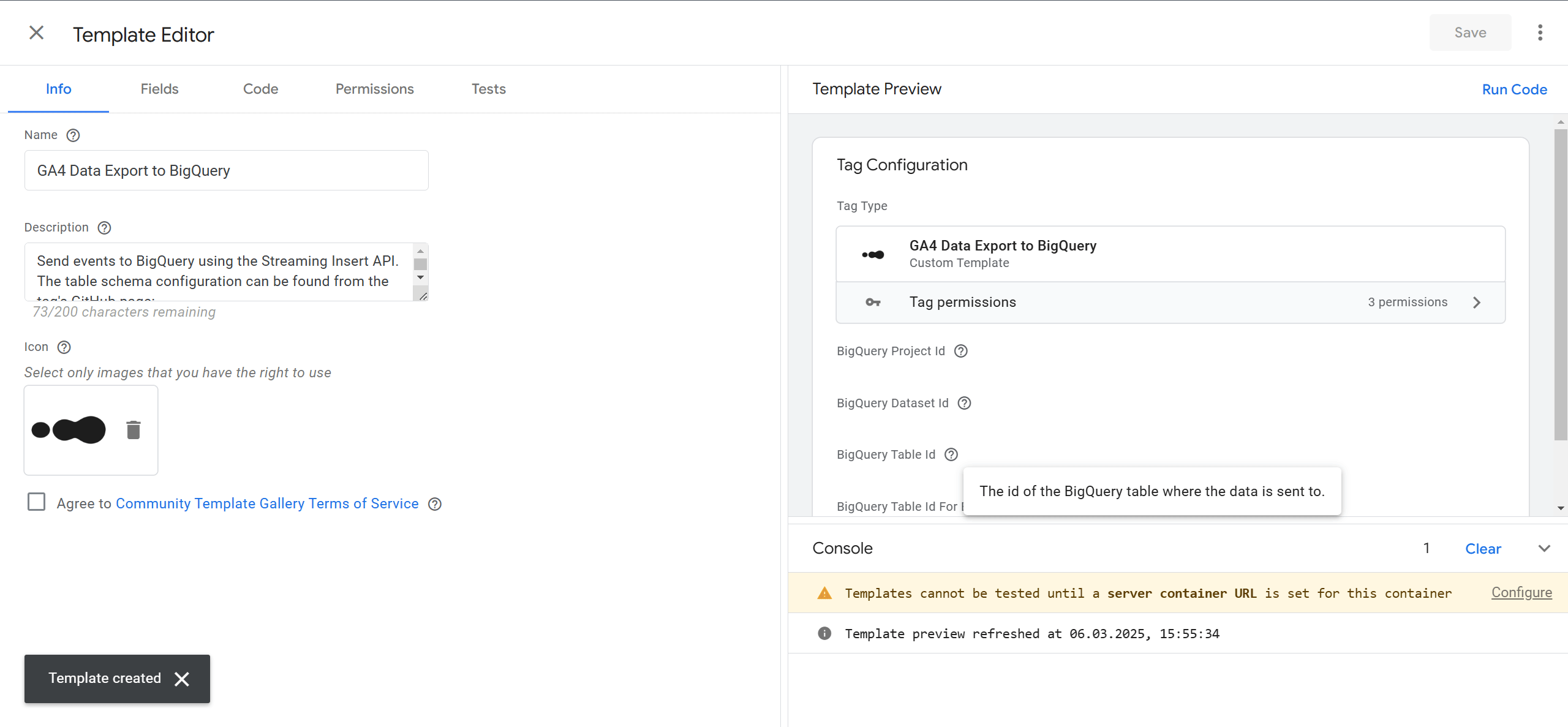
Вітаю! Ви успішно додали шаблон і далі залишилось зробити декілька кроків, щоб налаштувати його під ваші дані.
Налаштування в BigQuery
Для того, щоб налаштувати передачу даних в таблицю BigQuery, потрібно створити цю таблицю в BigQuery.
- Створюємо окремий датасет (або ви можете використати вже існуючий):
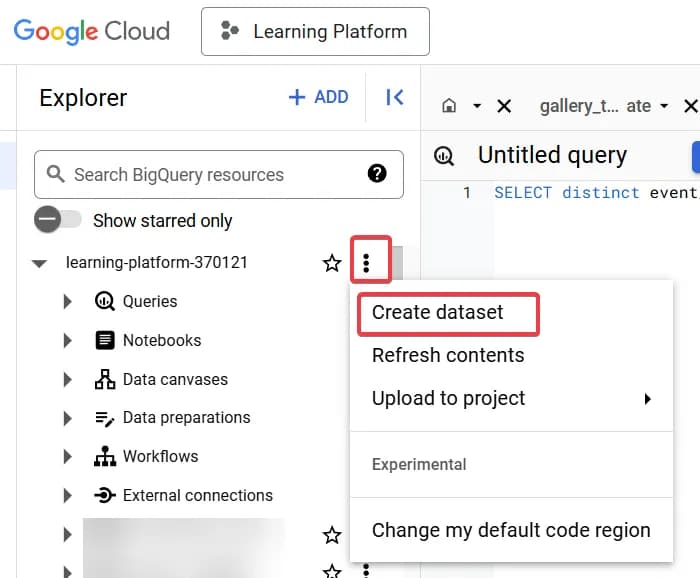
У відкритому вікні заповнюємо дані:
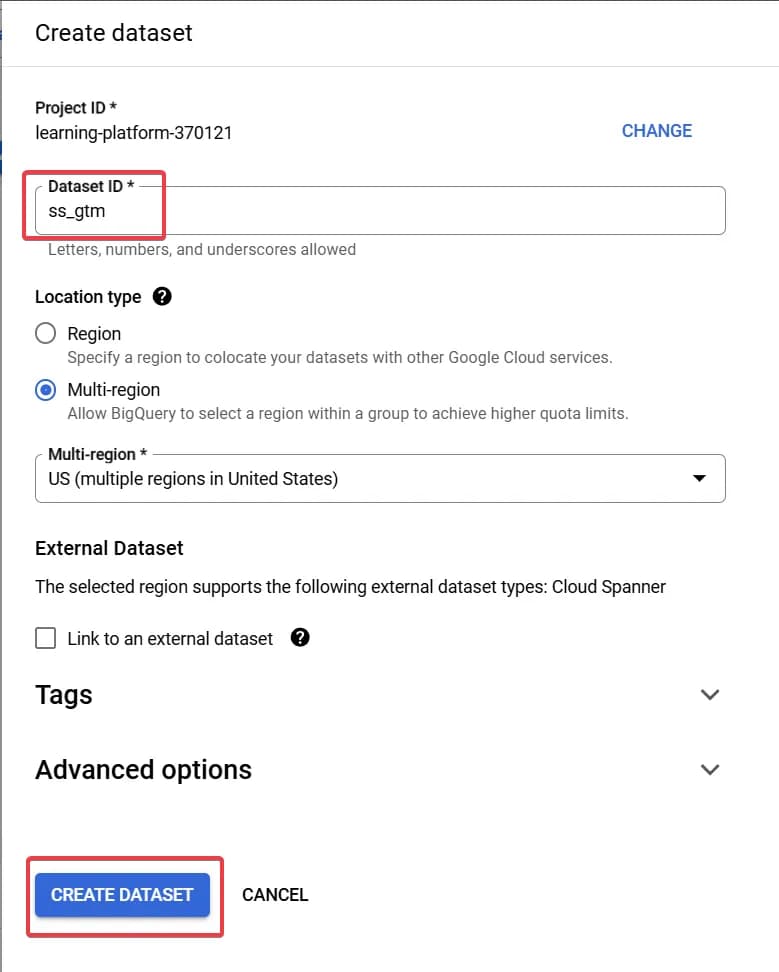
*назву датасету та регіон можете змінити на свої
2. Створюємо таблицю в цьому датасеті
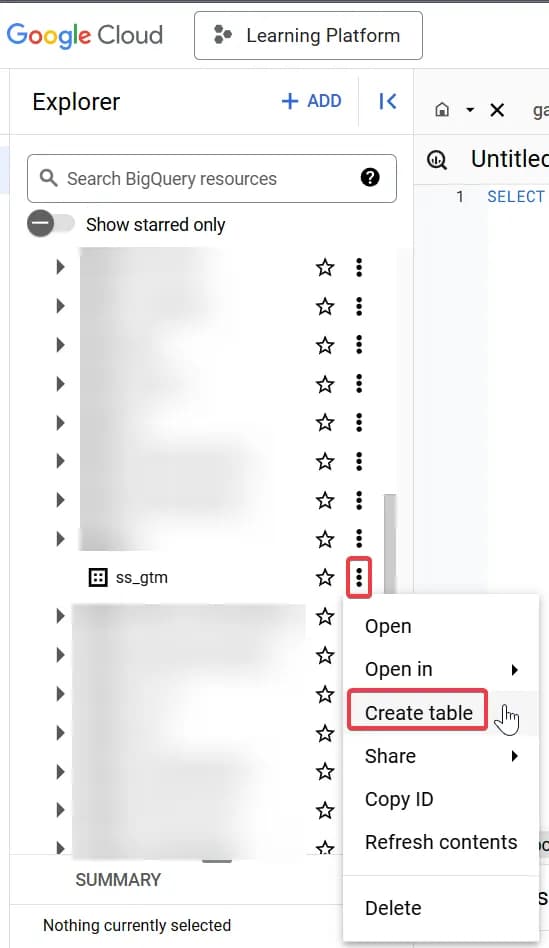
При створенні таблички вкажіть її назву та в налаштуваннях схеми увімкніть галочку Edit as text для того, щоб вставити підготовлену схему таблиці (копіюєте її повністю і просто вставляєте в поле, де вказано Insert). Далі зберігаємо.
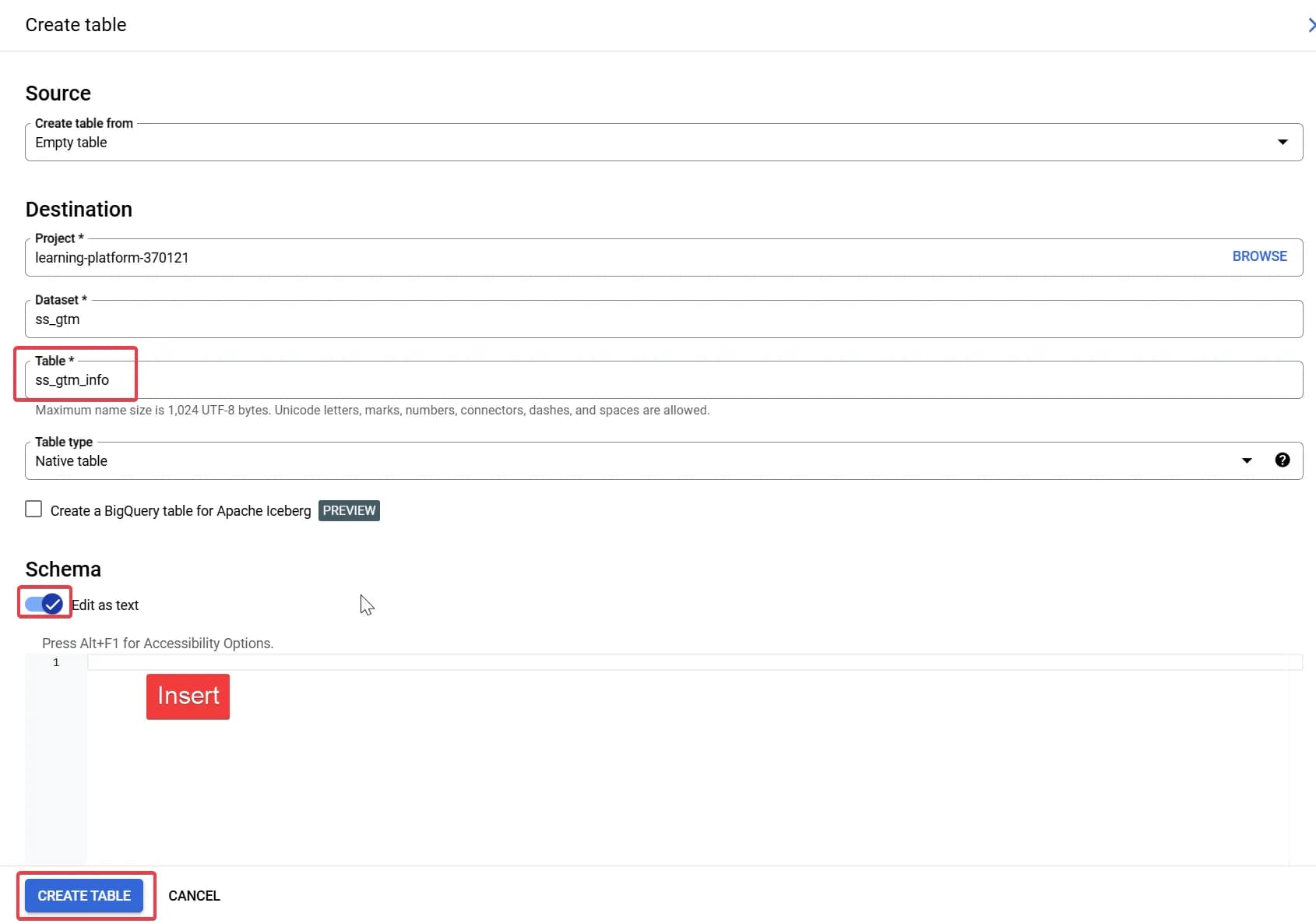
*назву таблиці можете змінити на свою
Важливо! Не забудьте налаштувати партиціювання та кластеризацію як вказано нижче:
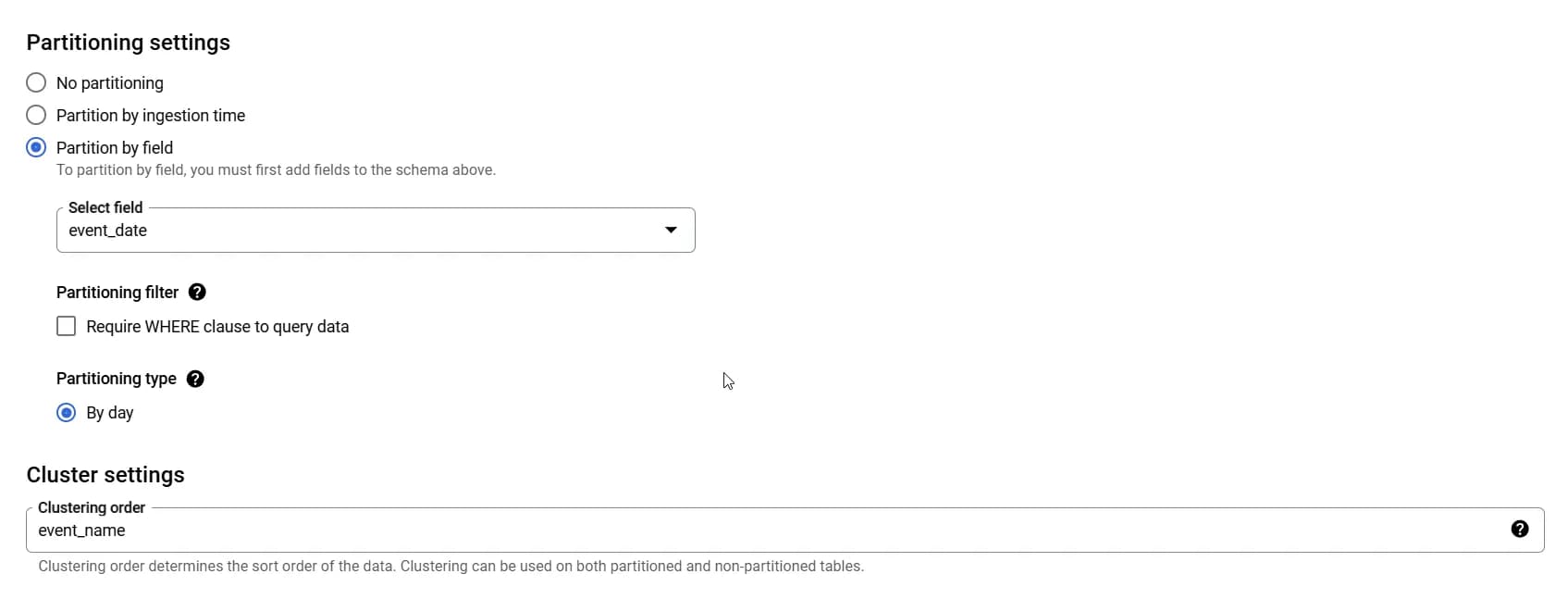
Далі зберігаємо таблицю (Клікаємо на CREATE TABLE).
В результаті цих налаштувань ви отримаєте таблицю з такою схемою:
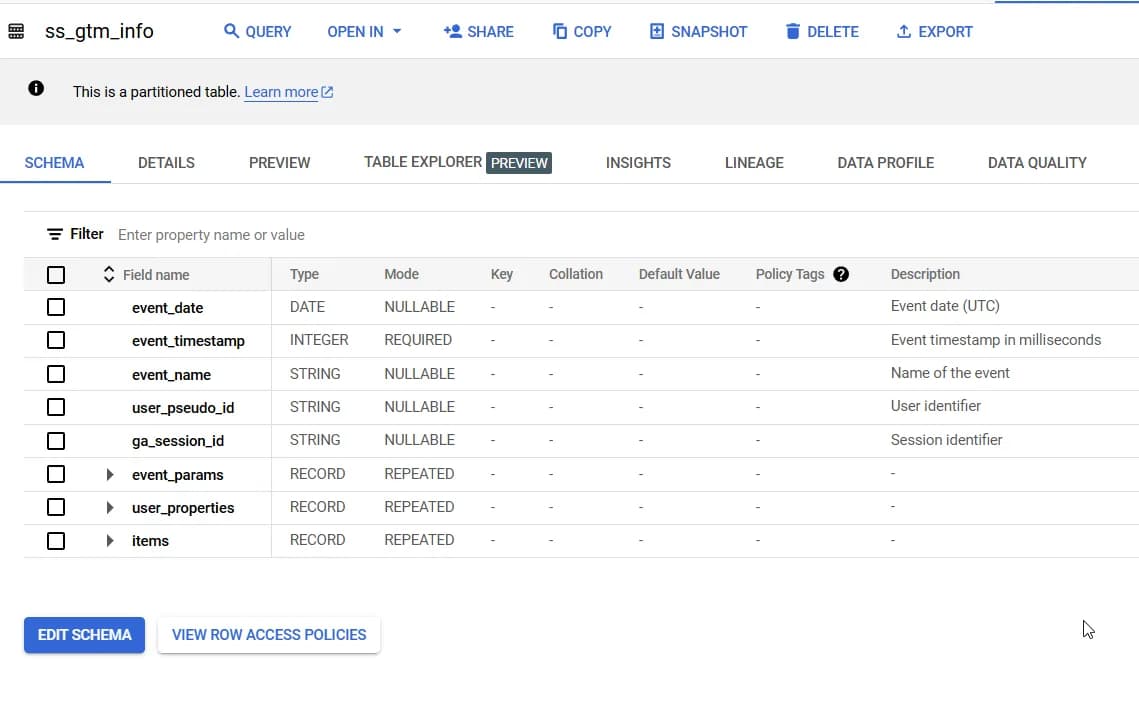
На цьому налаштування в BigQuery закінчені.
Налаштування в Server-Side GTM
Заповнення обов’язкових полів
- Створіть новий тег на основі нашого шаблону
Ми використовуємо тригер CN - GA4 за замовчуванням (записуються усі події, що й в GA4), але за потреби ви можете змінити його та записувати, наприклад, лише певні конкретні івенти.
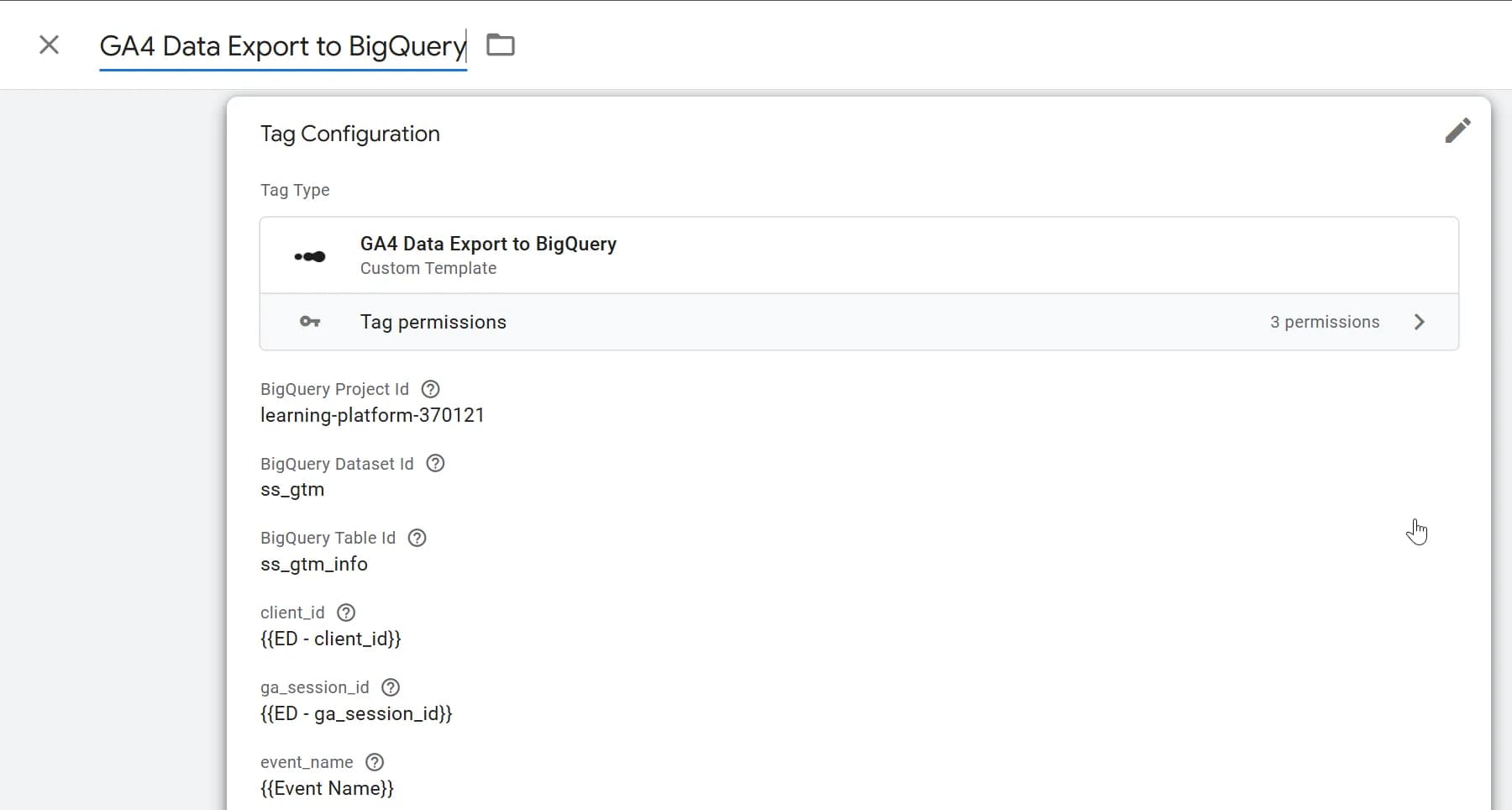
2. Заповніть усі обов’язкові поля тега даними:
- проєкт BigQuery (можна взяти з меню або в посиланні після project= )
- датасет з вашою таблицею на цьому проєкті BigQuery (в нашому прикладі це ss_gtm)
- ID таблиці (в нашому прикладі це ss_gtm_info)
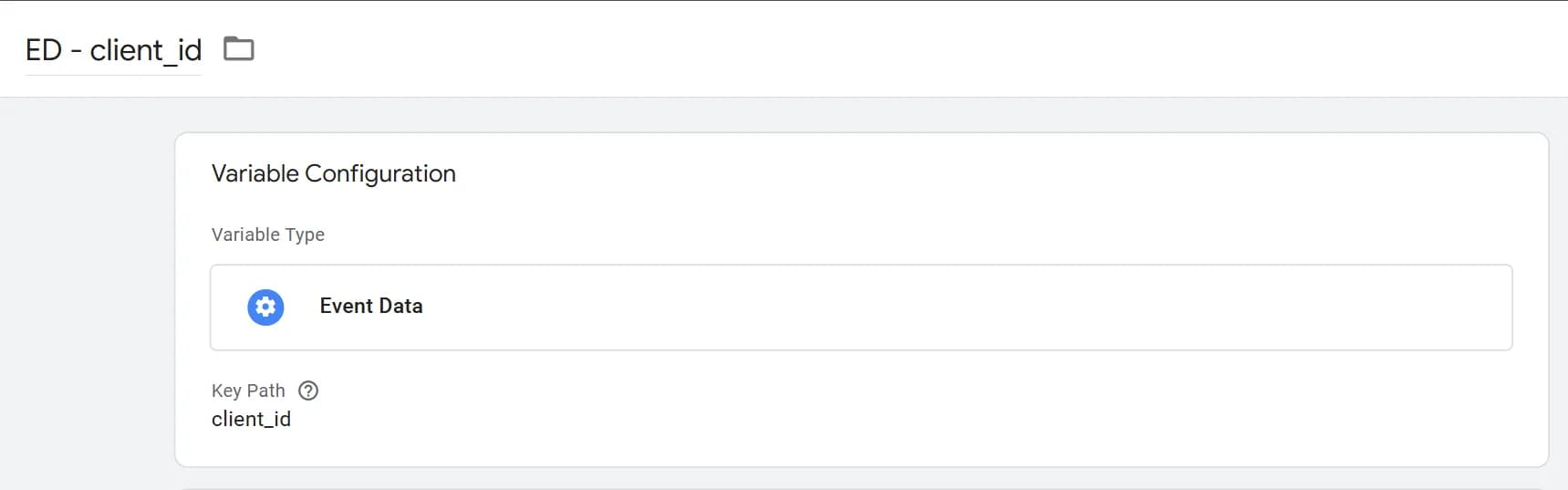
- client_id - створюємо змінну ED - client_id
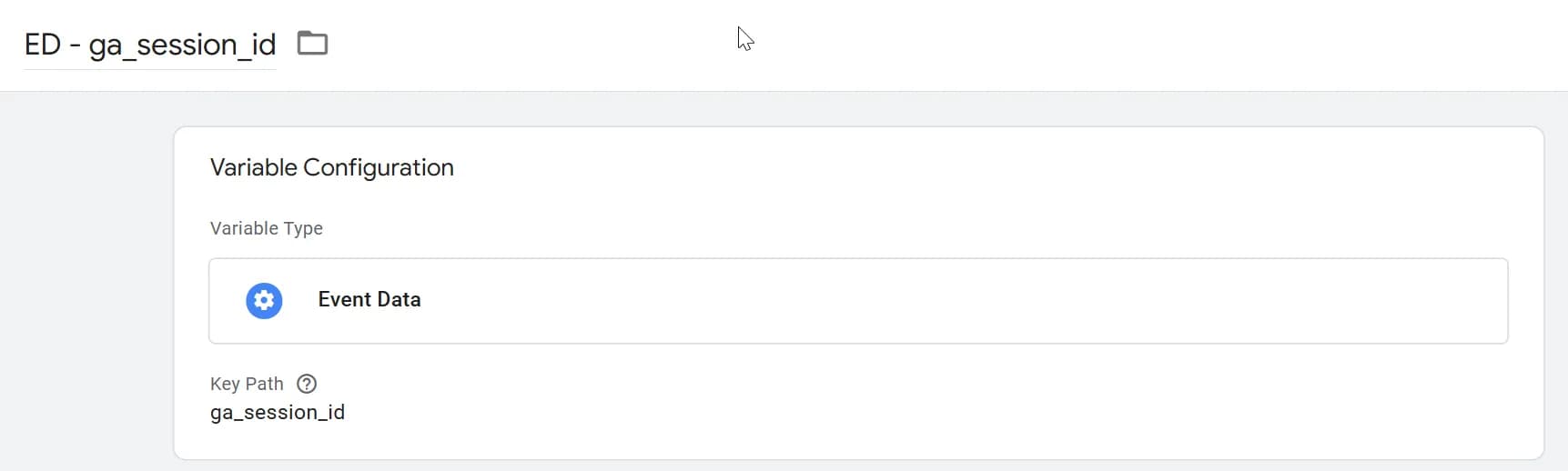
- ga_session_id - створюємо змінну ED - ga_session_id
- event_name - використовуємо стандартну змінну Event name
Звісно, для параметрів client_id, ga_session_id та event_name можна було б прописати дефолтні значення на рівні шаблону, але в цій версії ми цього не зробили)
В результаті у вас має вийти ось такий заповнений тег:
3. Перевірте коректність налаштувань в консолі дебагу
Якщо все вірно, то ви побачите подібний запис в консолі:
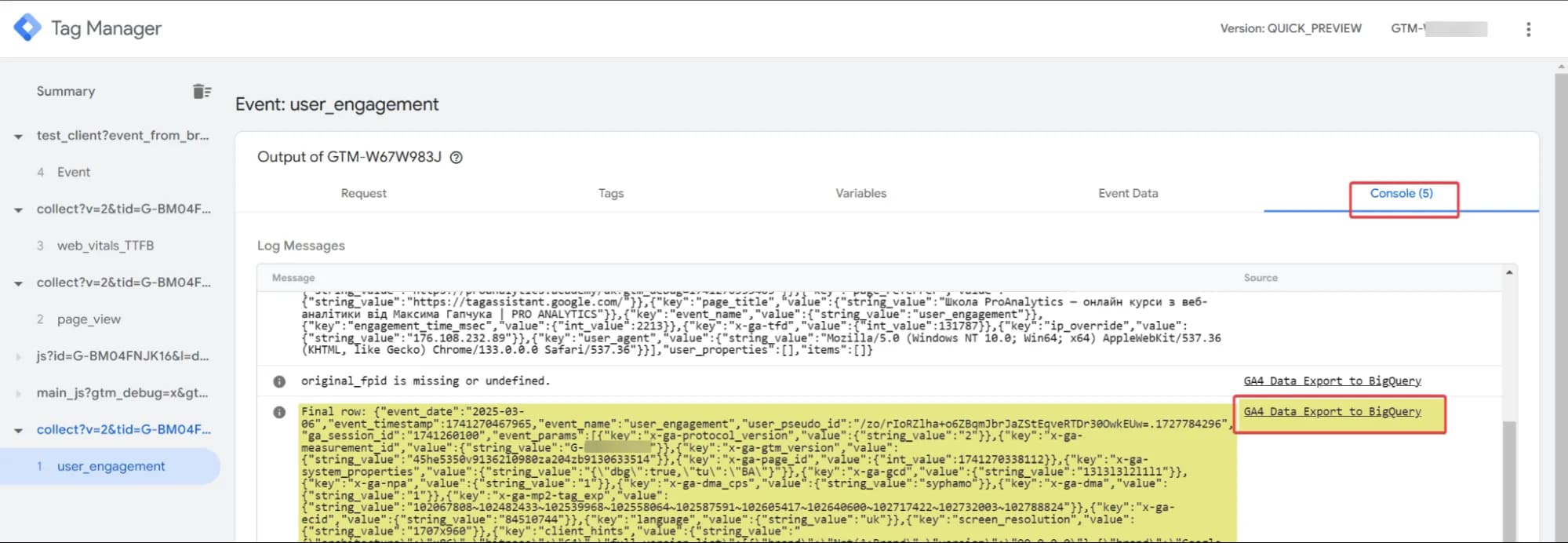
де в Source - назва вашого тегу і до нього великий запис з даними, що починається з Final row. І не лякайтесь, в BigQuery все буде виглядати набагато краще.
Зверніть увагу, що до вашого ж тегу буде й інший запис:

Цей запис не інформує про помилку, а попереджає, що поле original_fpid незаповнене. Так і має бути за поточних налаштувань. Як його заповнити і для чого це може бути потрібно я розповім пізніше.
4. Перевірте наявність даних в вашій таблиці BigQuery (дані в режимі прев’ю також будуть записуватись в поточній версії.
5. Якщо все ОК - опублікуйте контейнер.
Особливості, на які варто звернути увагу
В нашому шаблоні ми використовуємо часовий пояс по UTC. Ми вибрали саме цей варіант, так як UTC буде універсальним для юзерів з різних країн і його легше буде конвертувати у інший часовий пояс.
А для тих, хто прив'язаний до часового поясу в Україні (по Києву) ми додамо трошки корисного матеріалу в модифікаціях.
- Повторюсь, але ми не використовуємо всі-всі поля, що є в експорті з GA4: ми лише відокремили параметри на рівні події, користувача та окремо дані про товари для подій електронної комерції і окремо винесли основні поля: event_name, event_timestamp, event_date, user_pseudo_id та ga_session_id. Саме ці поля, на мій погляд, є найбільш популярними у запитах, тому прописали їх окремо.
- Також ми додали обробку, на наш погляд, корисних параметрів, як original_fpid та original_cid (в event_params), які потім можна використати для пост-обробки (детальніше про те, що це і для чого потрібно, можна почитати в модифікаціях).
Але перед тим, як говорити про модифікації, пропоную детально розібрати роботу шаблону.
Принцип роботи шаблону
Спочатку розберемо сам код.
- Імпортуємо необхідні модулі
const log = require('logToConsole');
const BigQuery = require('BigQuery');
const makeString = require('makeString');
const makeInteger = require('makeInteger');
const JSON = require('JSON');
const getTimestampMillis = require('getTimestampMillis');
const getAllEventData = require('getAllEventData');
const getType = require('getType');
const Object = require('Object');
const Math = require("Math");2. Використовуємо функції для роботи з датою, щоб вивести дані в форматі DATE з таймстемпу. Така складність пов'язана з тим, що API GTM Server-Side працює в середовищі пісочниці і деякі звичні JS функції там не доступні.
function calculateUTCDateFromTimestamp(timestampInMillis) {
const secondsInDay = 86400;
let timestampInSeconds = Math.floor(timestampInMillis / 1000);
return calculateDateFromTimestamp(timestampInSeconds);
}
function calculateDateFromTimestamp(timestampInSeconds) {
const daysInMonth = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31];
const epochYear = 1970;
const secondsInDay = 86400;
let dayssinceEpoch = Math.floor(timestampInSeconds / secondsInDay);
let year = epochYear;
while (dayssinceEpoch >= (isLeapYear(year) ? 366 : 365)) {
dayssinceEpoch = dayssinceEpoch - (isLeapYear(year) ? 366 : 365);
year = year + 1;
}
let month = 0;
while (dayssinceEpoch >= (month === 1 && isLeapYear(year) ? 29 : daysInMonth[month])) {
dayssinceEpoch = dayssinceEpoch - (month === 1 && isLeapYear(year) ? 29 : daysInMonth[month]);
month = month + 1;
}
const day = dayssinceEpoch + 1;
return year + "-" + padToTwoDigits(month + 1) + "-" + padToTwoDigits(day);
}
function isLeapYear(year) {
return (year % 4 === 0 && year % 100 !== 0) || (year % 400 === 0);
}
function padToTwoDigits(number) {
return (number < 10 ? "0" : "") + number;
}3. Транформуємо усі дані до 3 форматів: integer, string, float
function isValidValue(value) {
return value !== undefined && value !== null && value !== '';
}
function identifyDataType(fieldValue) {
if (typeof fieldValue === 'number') {
return makeInteger(fieldValue) === fieldValue ? 'int_value' : 'float_value';
}
return 'string_value';
}
function changeDataType(fieldValue) {
if (fieldValue === undefined || fieldValue === null) {
return null; }
if (typeof fieldValue === 'boolean') {
return fieldValue ? 1 : 0; // Convert true → 1, false → 0
}
if (typeof fieldValue === 'object') {
return JSON.stringify(fieldValue); // Convert objects to JSON string
}
return fieldValue;
}4. Створюємо об'єкт для вставки - формуємо структуру для таблиці
const row = {
event_date: calculateUTCDateFromTimestamp(getTimestampMillis()),
event_timestamp: getTimestampMillis(),
event_name: makeString(data.eventName),
user_pseudo_id: makeString(data.client_id),
ga_session_id: makeString(data.session_id),
event_params: [],
user_properties: [],
items: []
};5. Обробляємо items.
Записуємо дані, що знаходяться в масиві items. Якщо параметри відносяться до стандартних на рівні товару, то вони будуть записані в окремі зарезервовані поля таблиці в items (predefinedItemFields), якщо кастомні - в items.item_params у відповідному типі даних
const predefinedItemFields = [
"item_id",
"item_name",
"item_brand",
"item_variant",
"item_category",
"item_category2",
"item_category3",
"item_category4",
"item_category5",
"price_in_usd",
"price",
"quantity",
"item_revenue",
"item_refund",
"coupon",
"affiliation",
"location_id",
"item_list_id",
"item_list_name",
"item_list_index",
"promotion_id",
"promotion_name",
"creative_name",
"creative_slot"
];
function extractItems(eventData) {
if (!eventData.items || getType(eventData.items) !== 'array') {
return;
}
eventData.items.forEach(function (item) {
var processedItem = {};
Object.keys(item).forEach(function (key) {
var value = item[key];
if (getType(predefinedItemFields) === 'array' && predefinedItemFields.indexOf(key) > -1) {
processedItem[key] = isValidValue(value) ? changeDataType(value) : null;
}
else if (isValidValue(value)) {
var param = {
key: key,
value: {}
};
var fieldType = identifyDataType(value);
if (fieldType === 'int_value') {
param.value.int_value = changeDataType(value);
} else if (fieldType === 'float_value') {
param.value.float_value = changeDataType(value);
} else {
param.value.string_value = changeDataType(value);
}
processedItem.item_params = processedItem.item_params || [];
processedItem.item_params.push(param);
}
});
row.items.push(processedItem);
});
}6. Обробляємо event_params - записуємо все, окрім даних з основних полів, user_properties та items у відповідному типі даних.
function extractEventParams(eventData) {
Object.keys(eventData).forEach((key) => {
if (key !== 'items' && key !== 'x-ga-mp2-user_properties'&& key !== 'event_name' && key !== 'client_id' && key !== 'ga_session_id') {
const value = eventData[key];
if (isValidValue(value)) {
const param = {
key: key,
value: {}
};
const fieldType = identifyDataType(value);
if (fieldType === 'int_value') {
param.value.int_value = changeDataType(value);
} else if (fieldType === 'float_value') {
param.value.float_value = changeDataType(value);
} else {
param.value.string_value = changeDataType(value);
}
row.event_params.push(param);
}
}
});
}7. Обробляємо FPID (якщо він наявний) в тому форматі, який використовується в GA4 та додаємо у event_params
Ось приклад того, як виглядає fpid з cookie (виділено червоним прямокутником), для порівняння (виділила жовтим) в якому вигляді летить в аналітику вже після декодування.
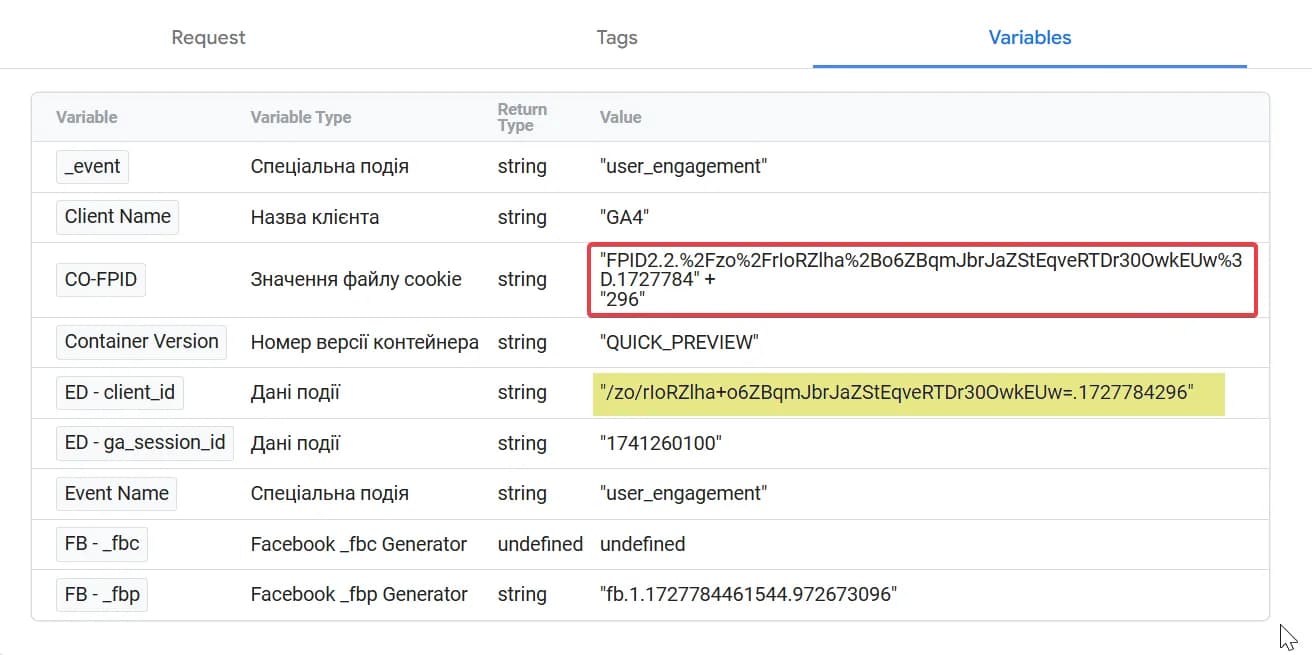
Тому ми прибираємо зі значення частинку FPID2.2 і також замінюємо значення URL-закодованих символів на відповідні:
if (data.original_fpid) {
var rawFpid = data.original_fpid.replace("FPID2.2.", "");// Remove prefix FPID2.2.
var decodedFpid = decodeURIComponentPolyfill(rawFpid);// Decode the value
log("Processed original_fpid: " + decodedFpid);
var originalFpidParam = { key: "original_fpid", value: {} };
originalFpidParam.value.string_value = makeString(decodedFpid);
row.event_params.push(originalFpidParam);
} else {
log("original_fpid is missing or undefined.");
}
function decodeURIComponentPolyfill(encodedStr) {
return encodedStr
.split("%2B").join("+")
.split("%2F").join("/")
.split("%3D").join("=")
.split("%20").join(" ")
.split("%3A").join(":")
.split("%2C").join(",")
.split("%3B").join(";")
.split("%40").join("@");
}8. Обробляємо user_properties - отримуємо дані, що передаються в x-ga-mp2-user_properties та записуємо у потрібному типі даних.
function extractUserProperties(eventData) {
if (
eventData['x-ga-mp2-user_properties'] &&
typeof eventData['x-ga-mp2-user_properties'] === 'object'
) {
const userProps = eventData['x-ga-mp2-user_properties'];
Object.keys(userProps).forEach((key) => {
const value = userProps[key];
if (isValidValue(value)) {
const param = {
key: key,
value: {}
};
const fieldType = identifyDataType(value);
// Explicitly assign data type key
if (fieldType === 'int_value') {
param.value.int_value = changeDataType(value);
} else if (fieldType === 'float_value') {
param.value.float_value = changeDataType(value);
} else {
param.value.string_value = changeDataType(value);
}
row.user_properties.push(param);
}
});
}
}9. Отримуємо всі дані та викликаємо функції для обробки даних на рівні товарів, події та юзера.
const eventData = getAllEventData();
if (eventData && typeof eventData === 'object') {
extractItems(eventData);
extractEventParams(eventData);
extractUserProperties(eventData);
}10. Логуємо об’єкт для вставки.
log("Final row: " + JSON.stringify(row));11. Прописуємо конфігурацію для основної таблиці BigQuery.
const connectionInfo = {
projectId: data.bqProject,
datasetId: data.bqDataset,
tableId: data.bqTable
};12. Прописуємо конфігурацію для резервної таблиці BigQuery (журнал помилок).
const connectionInfoFallback = {
projectId: data.bqProject,
datasetId: data.bqDataset,
tableId: data.bqFallbackTable // table name for logs(the same datasetId)
};13. Ігноруємо невідомі поля, щоб уникнути помилок.
const options = { ignoreUnknownValues: true };14. Вставляємо дані в основну таблицю BigQuery, і якщо виникає помилка, логуємо її та записуємо у резервну таблицю, викликаючи gtmOnSuccess() у разі успіху або gtmOnFailure() у разі повторної невдачі.
BigQuery.insert(connectionInfo, [row], options, data.gtmOnSuccess, (err) => {
if (err) {
log("BigQuery insert error: " + JSON.stringify(err));
const rowFallback = {
timestamp: Math.ceil(getTimestampMillis() / 1000),
logs: JSON.stringify(err)
};
BigQuery.insert(connectionInfoFallback, [rowFallback], options, data.gtmOnSuccess, (err) => {
if (err) {
log("BigQuery insert error: " + JSON.stringify(err));
data.gtmOnFailure();
} else {
log("BigQuery InfoFallback insert successful");
data.gtmOnSuccess();
}
});
data.gtmOnFailure();
} else {
log("BigQuery insert successful");
data.gtmOnSuccess();
}
});Окрім коду ще є два таби, які варто трохи прокоментувати:
- Fields
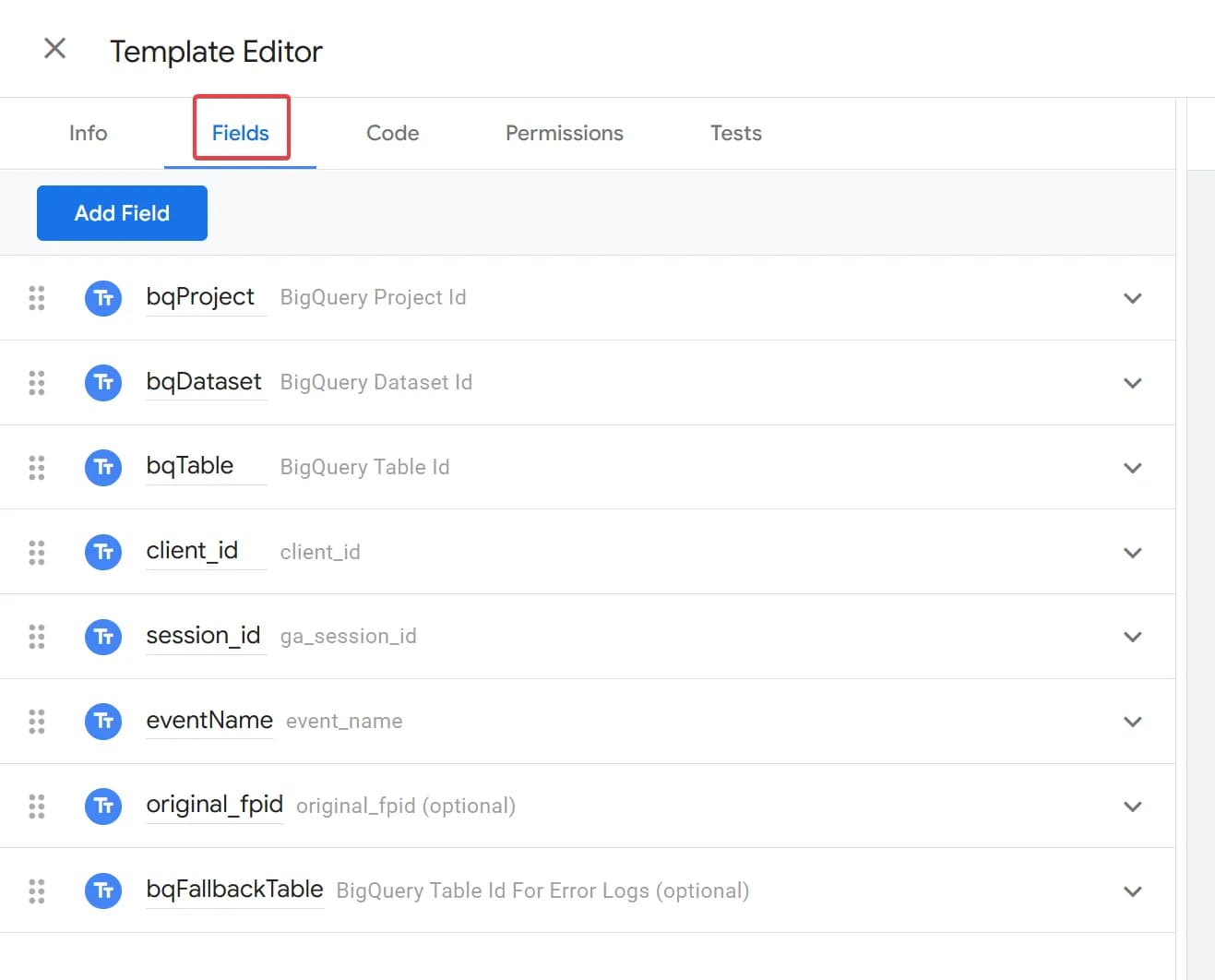
Усі поля типу Text input, де принцип їхнього заповнення наступний: перша назва (чорним) - назва змінної з нашого коду, друга (сірим) - назва, яку ви хочете відобразити в тезі до відповідного поля.
Саме тут створюються поля, які ви бачите в тезі на основі шаблону:
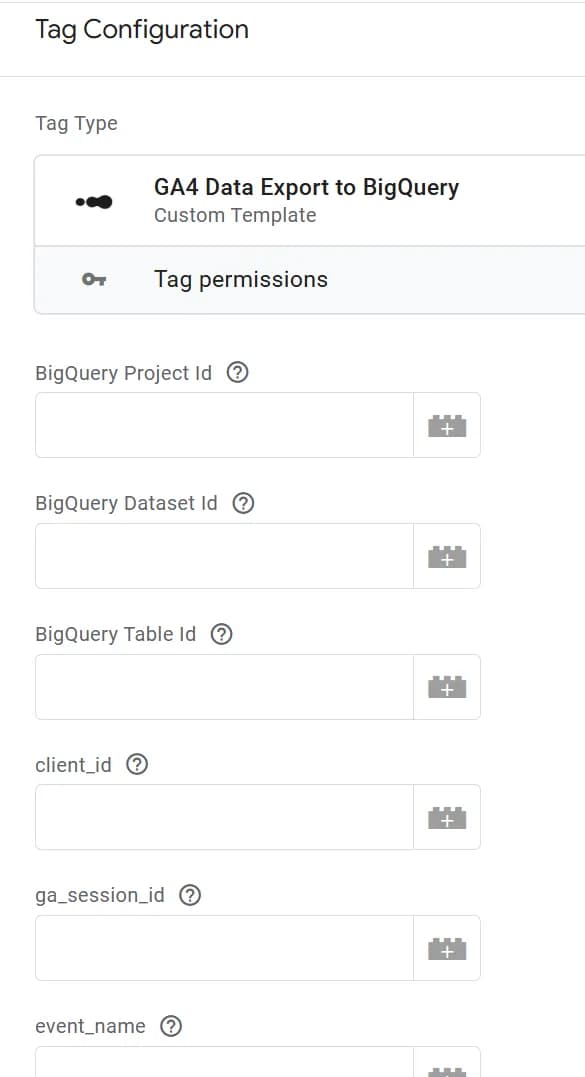
2. Permissions
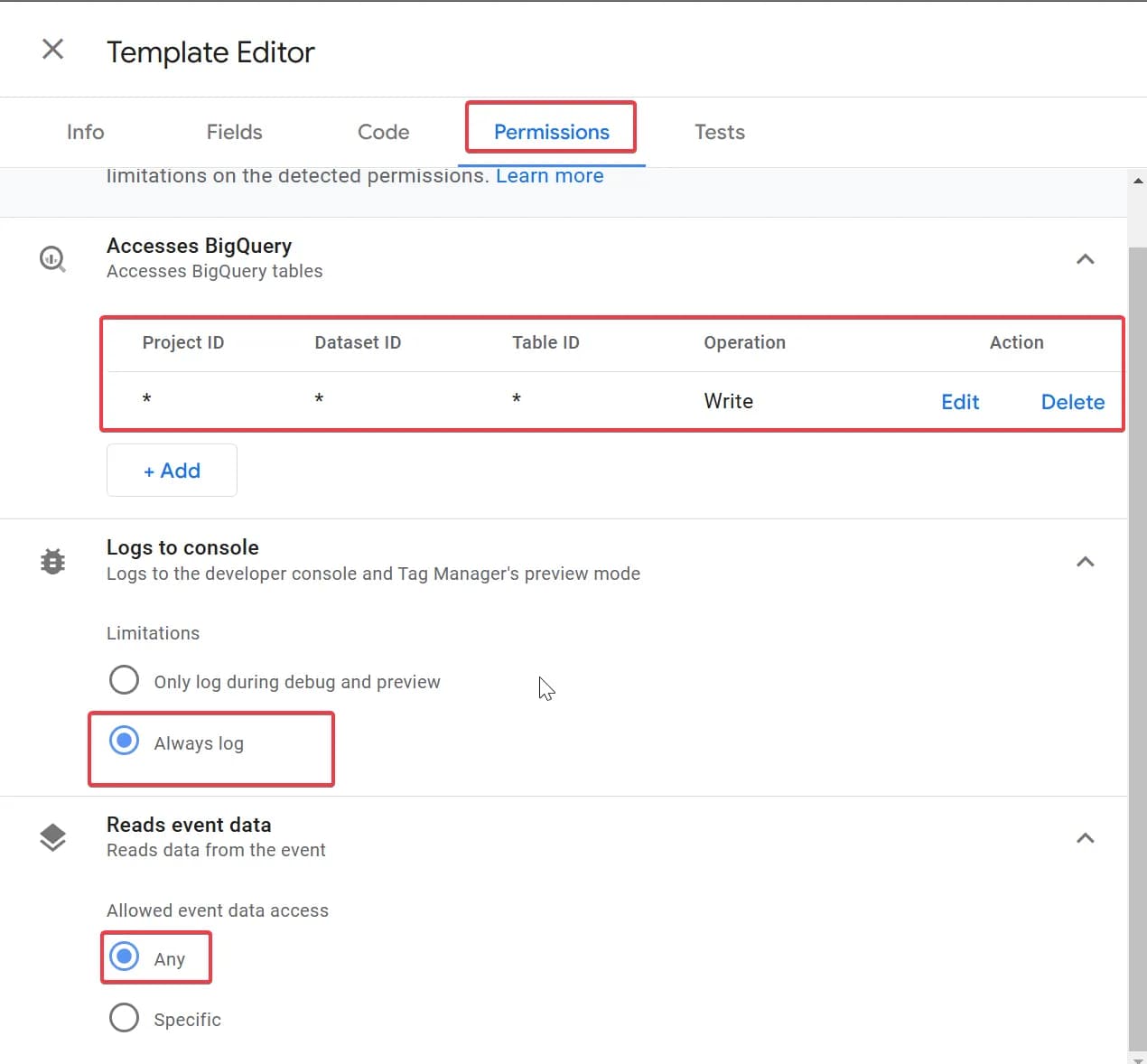
- Accesses BigQuery ми вказали можливість запису даних у будь-який проєкт, датасет та таблицю. А вже в окремі поля тегу прописуємо необхідні ID.
- Logs to console в шаблоні обрано Always log, але щоб зменшити кількість логів ви можете залишити логування тільки для режиму дебагу.
- Reads event data також не вводили ніяких обмежень, бо ми хочемо отримувати всі наявні дані з подій.
Можливі модифікації шаблону
Передача оригінального FPID та cid в параметрах
Згідно малюнку нижче (його взято зі статті Simo Ahava) аналітика повинна отримувати cid - фінальний ідентифікатор клієнта за наступною логікою:
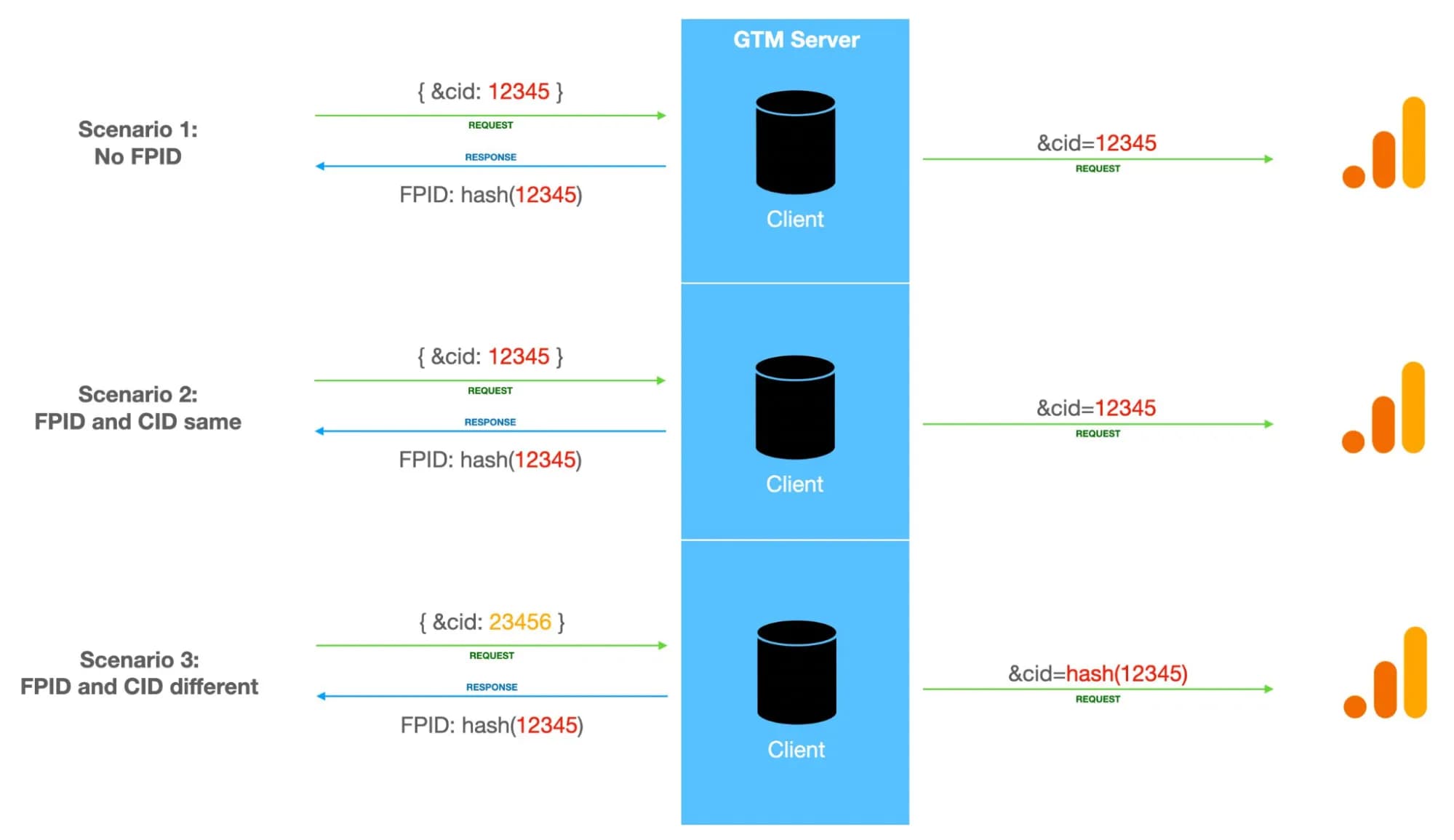
- Якщо ще немає fpid, то в якості cid відправляється оригінальний cid (12345) в GA4, а у відповідь серверний GTM назначає нам fpid = хешований cid (hash(12345)).
- Якщо fpid = хешований cid (hash(12345)) - відправляється оригінальний cid (12345) в GA4.
- Якщо наявний fpid вже не дорівнює хешованому cid(hash(12345) <> 23456), тобто cid вже змінився - відправляється оригінальний fpid(hash(12345)).
Під оригінальними я маю на увазі ті, що летять з вхідним запитом в серверному GTM.
І хоча з картинки ми розуміємо, що це один і той самий юзер, в якого змінювалась кука _ga, в GA4 це все одно буде два різні користувачі - перший буде об'єднувати в собі дії зі сценаріїв 1 та 2. А другий міститиме події зі сценарію 3.
Якщо вам підходить ідентифікація користувачів, як в інтерфейсі аналітики, то нічого змінювати не треба, якщо хочете ще детальніше ідентифікувати юзерів - можна скористатись об’єднанням пар в контейнери.
Маючи всі пари оригінальних cid та fpid можна ідентифікувати юзерів ще більш точно - для кожного сформувати final_fpid (контейнер), який буде об’єднувати всі комбінації:
| original_cid | original_fpid | final_cid | final_fpid |
|---|---|---|---|
12345 | - | 12345 | hash(12345) |
12345 | hash(12345) | 12345 | hash(12345) |
23456 | hash(12345) | hash(12345) | hash(12345) |
- original_cid - cid з вхідного запиту
- original_fpid - fpid з вхідного запиту
- final_cid - cid, що летить в аналітику (визначає юзера по логіці GA4)
- final_fpid - фінальний ідентифікатор клієнта, який визначається за допомогою додаткової обробки значень з перших двох колонок
Оскільки передача цих оригінальних параметрів не є обов'язковою і її можна додати за бажанням, то в шаблоні ми використовували методи обробки цих даних таким чином, щоб лише при явному додаванні параметрів дані записувались в табличку. В іншому випадку вони будуть відсутні.
Як саме витягти FPID?
В окреме поле тегу вставляємо попередньо підготовлене значення з куки FPID (змінна CO - FPID) і далі вже в шаблоні робимо обробку та декодування його значення саме з поля тегу.
Все, що вам потрібно зробити зі свого боку - створити змінну CO - FPID і додати її в поле тегу:
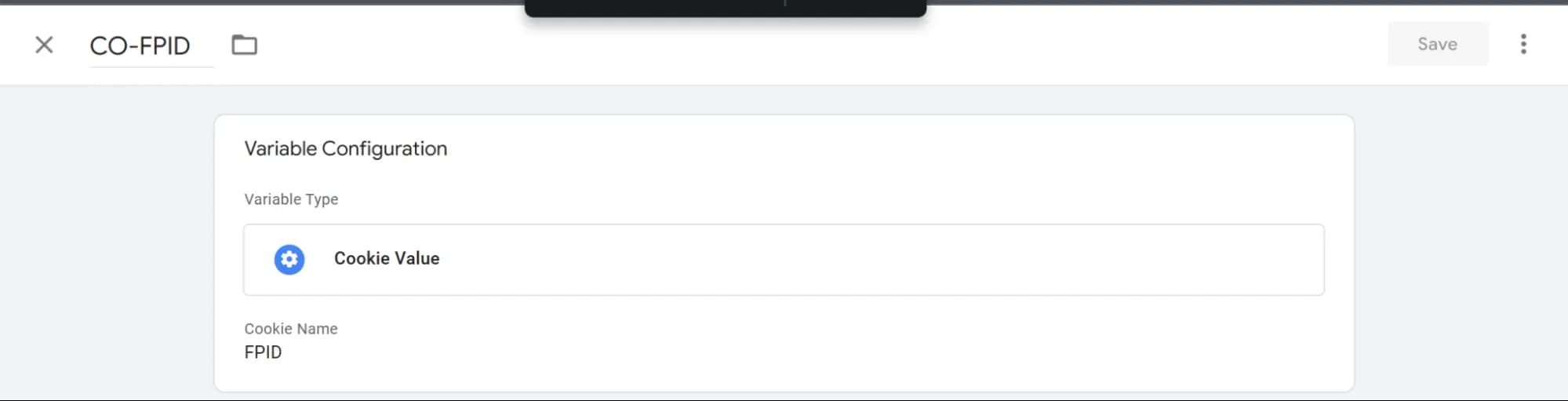
Якщо ви зробили коректні налаштування, то цей параметр original_fpid з’явиться у вас в event_params у вашій таблиці BQ.
Звісно, є альтернативні способи витягування fpid з куки, наприклад, як описано в довідці по API.
Звідки взяти original_cid?
Один зі способів буде аналогічний тому, який я розповідала для FPID вище. В серверному GTM ви можете створити змінну, де витягнете дані з куки _ga:
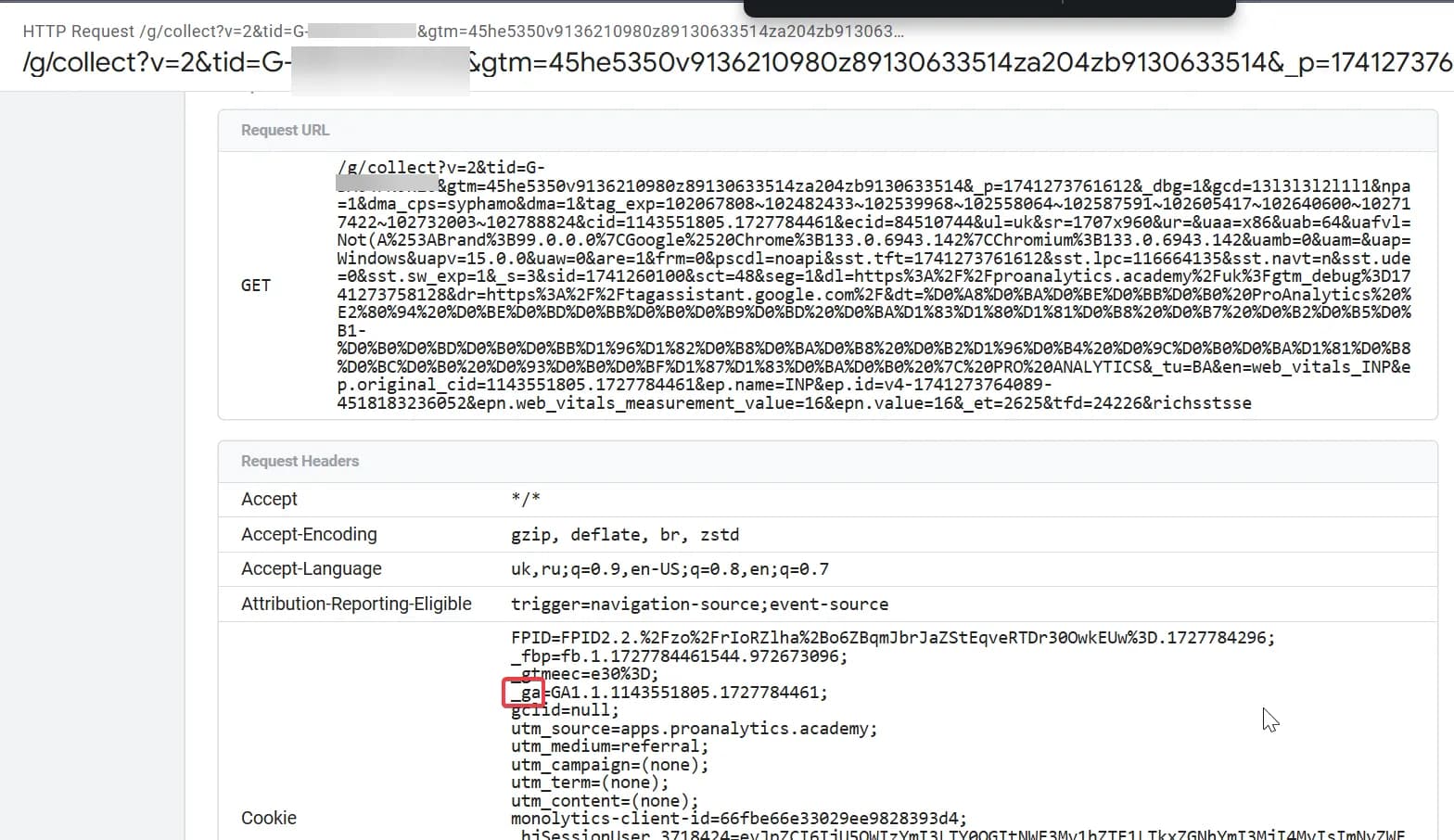
Але для того щоб показати різноманіття способів вирішення такої задачі я покажу інший приклад - на стороні звичайного GTM.
Cтворюємо змінну Custom JavaScript на основі значення з куки _ga:
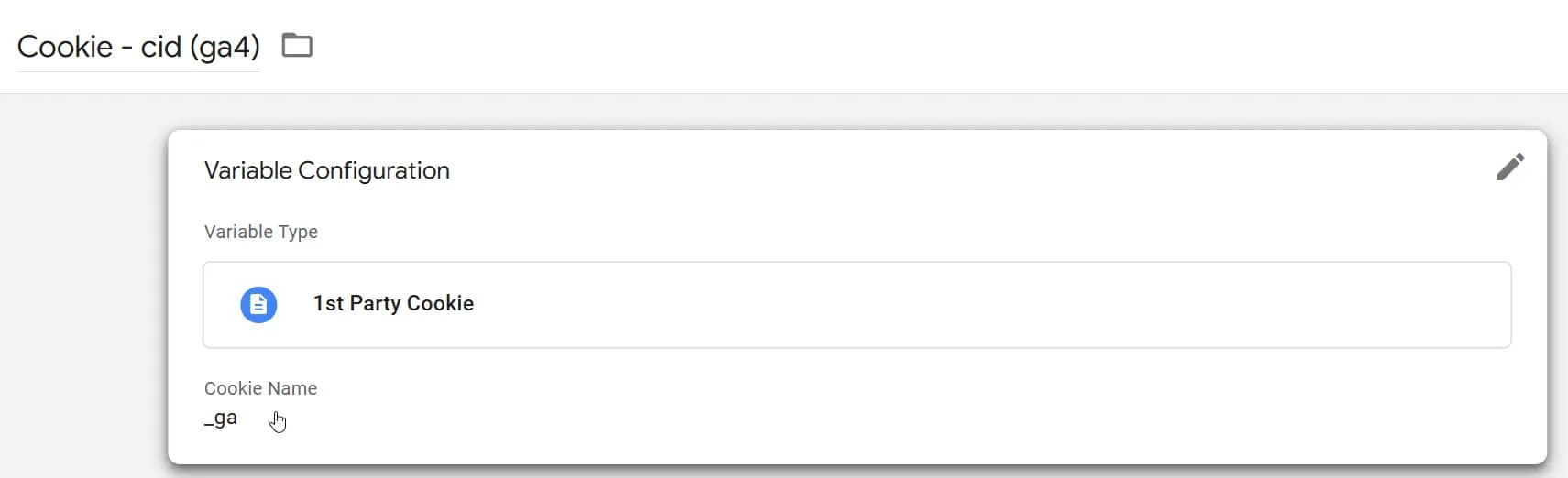
Далі зводимо до потрібного формату.
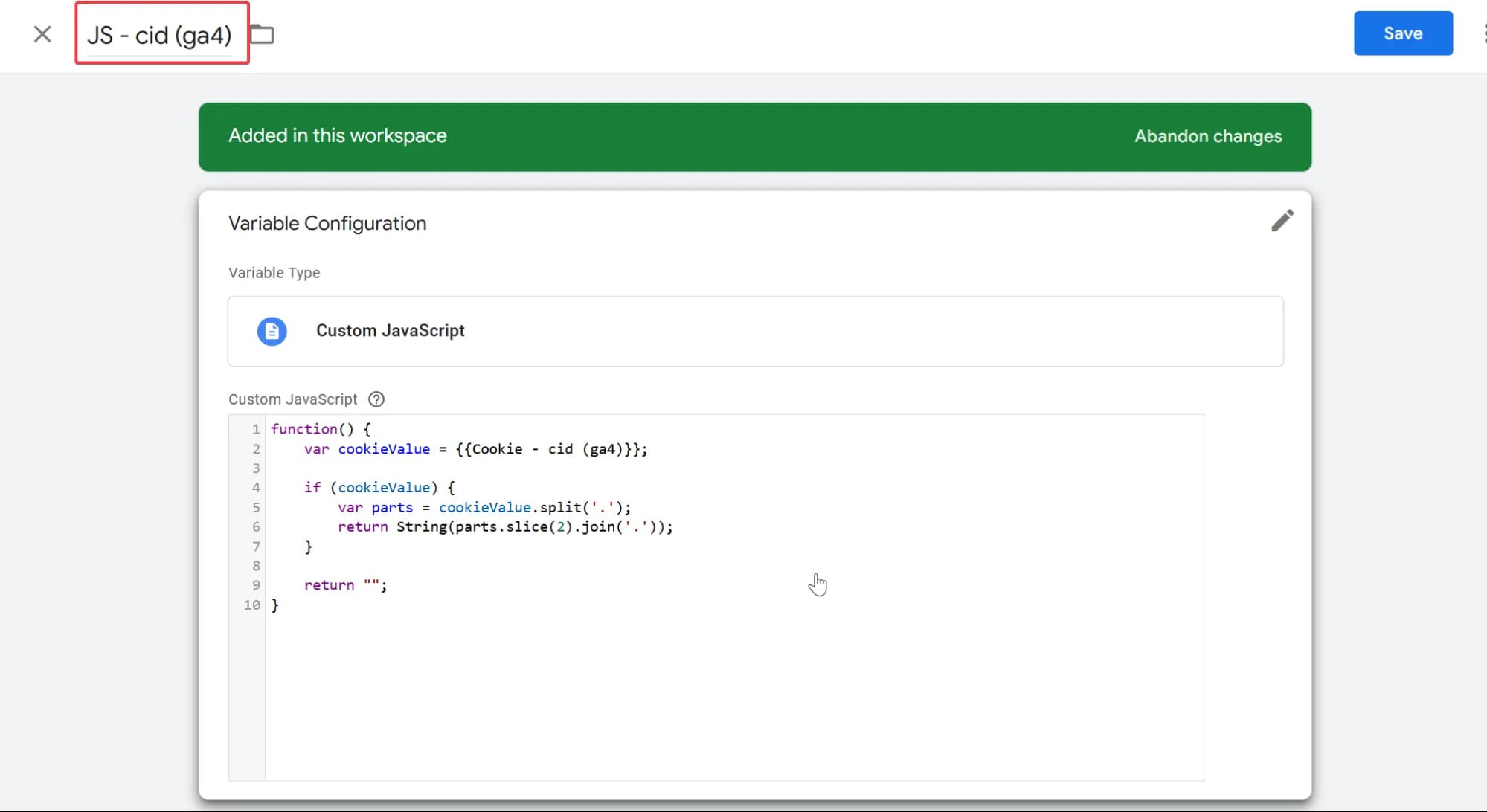
Код для витягування cid:
function() {
var cookieValue = {{Cookie - cid (ga4)}};
if (cookieValue) {
var parts = cookieValue.split('.');
return String(parts.slice(2).join('.'));
}
return "";
}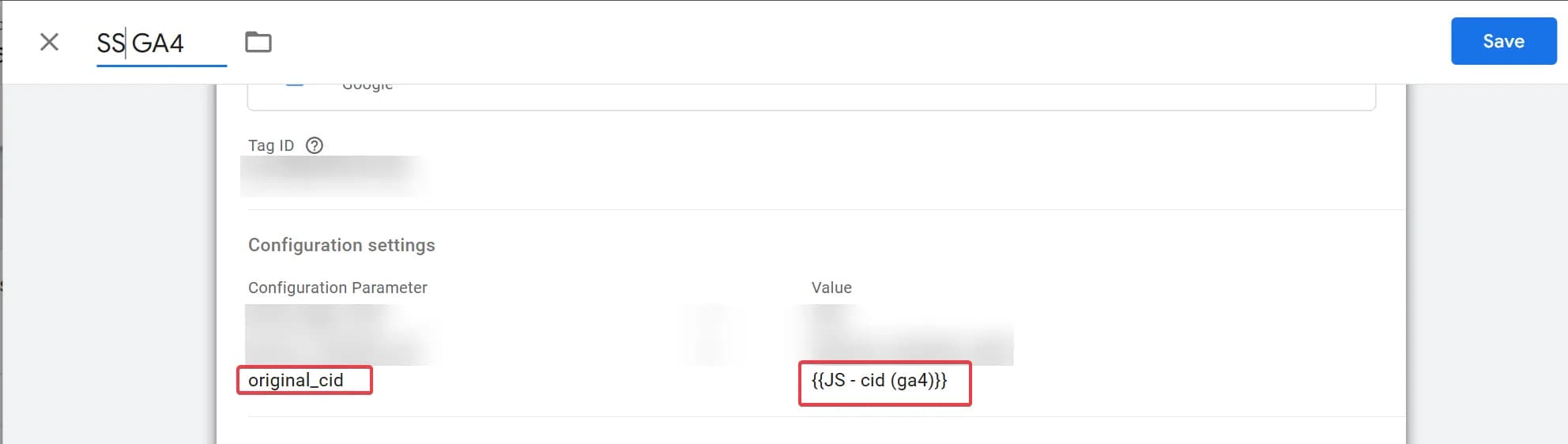
І це все, додаткових налаштувань в серверному GTM робити не потрібно. Цей параметр з’явиться у вас в event_params в таблиці BigQuery.
Який би спосіб ви не вибрали - ось такі параметри ви побачите після налаштувань:
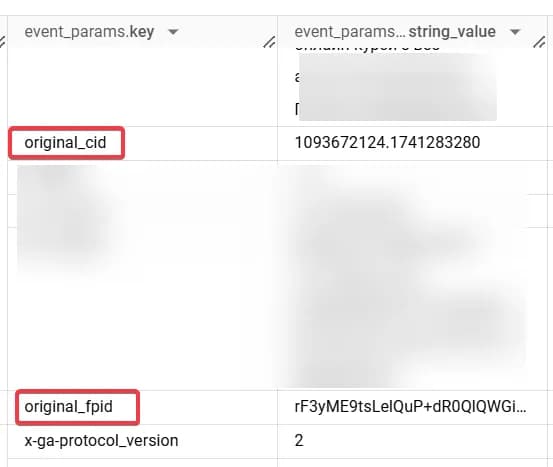
Відокремлення\фільтрація даних з дебагу
Разом з подіями ми отримуємо системні параметри, серед яких є параметр, який відображає режим дебагу.
Ось тут його можна знайти в Event Data:
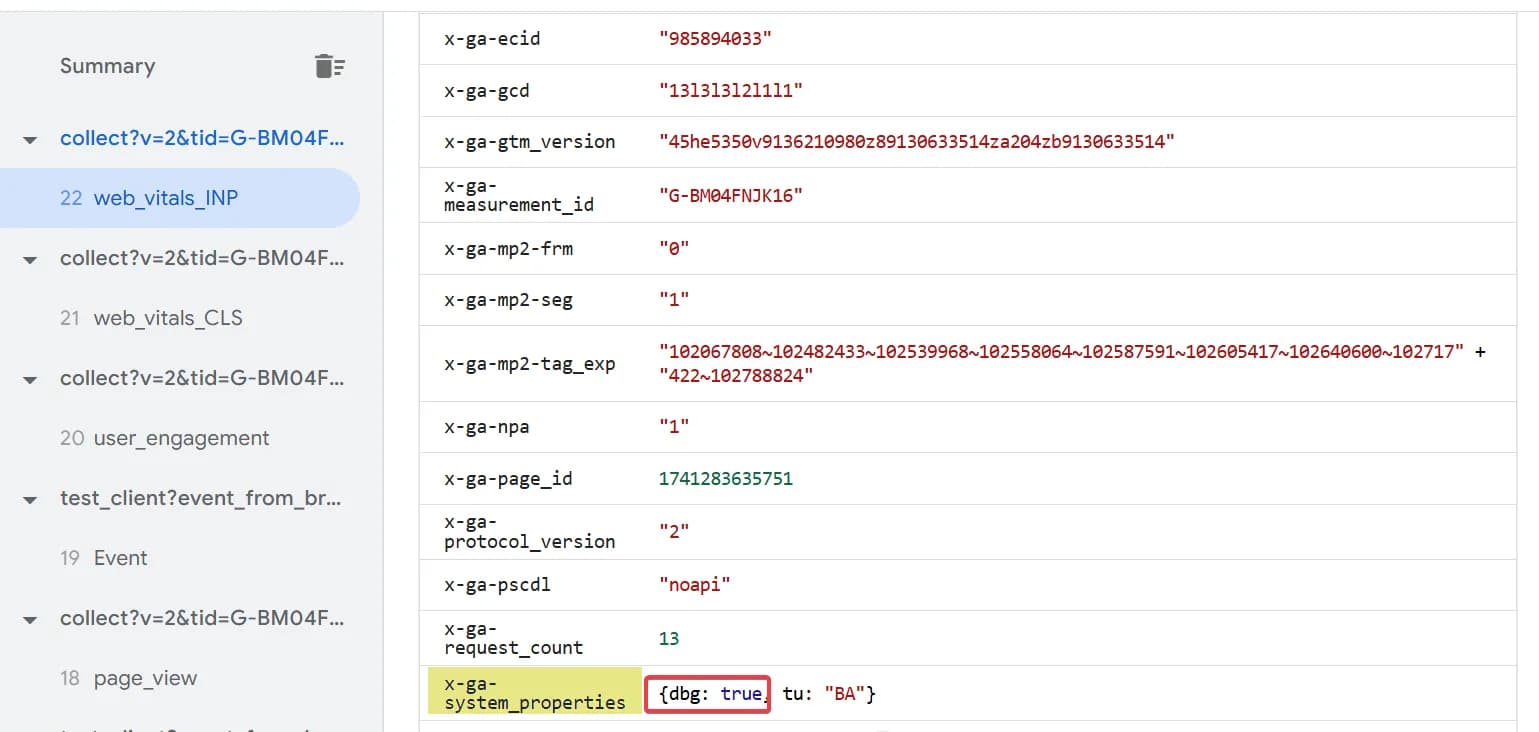
Для реальних подій dbg буде відсутнім.
Тому, якщо ви хочете, щоб дані з прев’ю не потрапляли у вашу таблицю, то ви можете додати частинку коду в шаблон для фільтрації таких подій і заборонити їхню передачу в BigQuery.
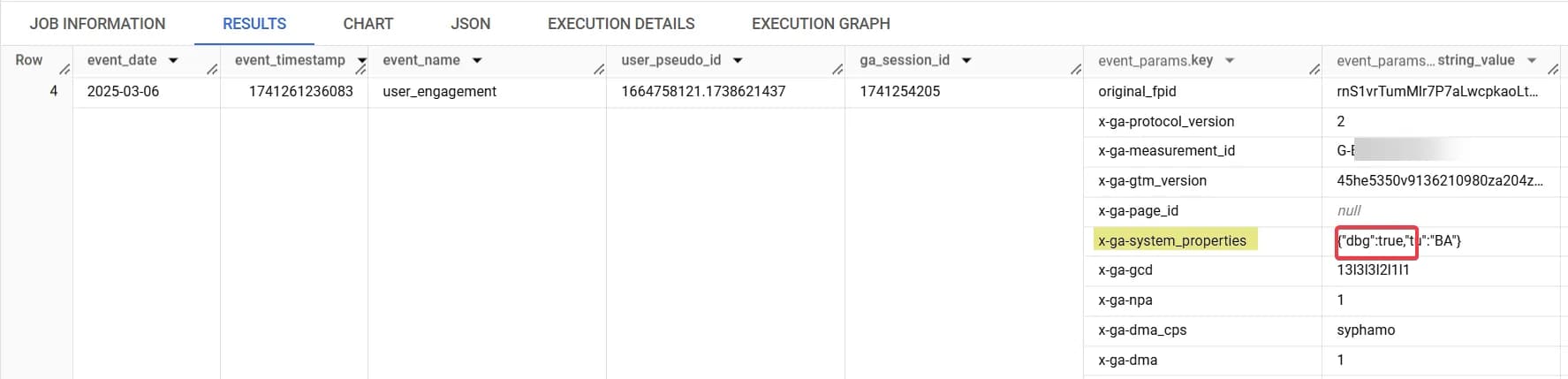
Або ж, як альтернативу, ви можете вже в BigQuery фільтрувати такі події у запитах, звертаючись до цього значення:
Визначення дати в часовому поясі GA4
Як я писала раніше, зараз в шаблоні дата записується по UTC.
Але якщо вам потрібно звести дані по аналогії з експортом GA4, то event_date краще отримати по часовому поясу, який використовується в інтерфейсі GA4.
Оскільки в нас багато клієнтів саме з України, то ми вже підготували готове рішення для визначення дати по Києву.
Якщо ви думаєте, що потрібно змінити пару рядків коду, то ви помиляєтесь:)
Server-Side GTM не має доступу до повного набору стандартних API JavaScript, тому довелось трошки покопатись з реалізацією.
Для отримання дати по Києву вам достатньо замінити шматочок скрипта з цього пункту на наступний:
// Функція для обчислення дати по Києву (YYYY-MM-DD)
function calculateKyivDateFromTimestamp(timestampInMillis) {
const secondsInDay = 86400; // Секунди в добі
const utcOffsetSeconds = 2 * 60 * 60; // Зміщення UTC+2 у секундах
const dstOffsetSeconds = 1 * 60 * 60; // Літній час: +1 година
// Перетворення мітки часу в секунди
let timestampInSeconds = Math.floor(timestampInMillis / 1000);
// Додаємо зміщення UTC+2
timestampInSeconds = timestampInSeconds + utcOffsetSeconds;
// Перевіряємо, чи діє літній час
const year = calculateYearFromTimestamp(timestampInSeconds);
const dstStart = calculateDstStartTimestamp(year); // Початок DST
const dstEnd = calculateDstEndTimestamp(year); // Кінець DST
if (timestampInSeconds >= dstStart && timestampInSeconds < dstEnd) {
timestampInSeconds = timestampInSeconds + dstOffsetSeconds; // Додаємо 1 годину, якщо DST
}
return calculateDateFromTimestamp(timestampInSeconds);
}
// Функція для обчислення дати і часу по Києву (YYYY-MM-DD HH:MM:ss)
function calculateKyivDateTimeFromTimestamp(timestampInMillis) {
const secondsInDay = 86400; // Секунди в добі
const utcOffsetSeconds = 2 * 60 * 60; // Зміщення UTC+2 у секундах
const dstOffsetSeconds = 1 * 60 * 60; // Літній час: +1 година
// Перетворення мітки часу в секунди
let timestampInSeconds = Math.floor(timestampInMillis / 1000);
// Додаємо зміщення UTC+2
timestampInSeconds = timestampInSeconds + utcOffsetSeconds;
// Перевіряємо, чи діє літній час
const year = calculateYearFromTimestamp(timestampInSeconds);
const dstStart = calculateDstStartTimestamp(year); // Початок DST
const dstEnd = calculateDstEndTimestamp(year); // Кінець DST
if (timestampInSeconds >= dstStart && timestampInSeconds < dstEnd) {
timestampInSeconds = timestampInSeconds + dstOffsetSeconds; // Додаємо 1 годину, якщо DST
}
// Визначаємо дату
const date = calculateDateFromTimestamp(timestampInSeconds);
// Визначаємо години, хвилини та секунди
const hours = Math.floor((timestampInSeconds % secondsInDay) / 3600);
const minutes = Math.floor((timestampInSeconds % 3600) / 60);
const seconds = timestampInSeconds % 60;
// Форматуємо час у формат HH:MM:SS
const formattedTime =
padToTwoDigits(hours) +
":" +
padToTwoDigits(minutes) +
":" +
padToTwoDigits(seconds);
// Об'єднуємо дату і час
return date + " " + formattedTime;
}
// Функція для обчислення року з мітки часу
function calculateYearFromTimestamp(timestampInSeconds) {
const secondsInDay = 86400;
const epochYear = 1970;
let dayssinceEpoch = Math.floor(timestampInSeconds / secondsInDay);
let year = epochYear;
while (dayssinceEpoch >= (isLeapYear(year) ? 366 : 365)) {
dayssinceEpoch = dayssinceEpoch - (isLeapYear(year) ? 366 : 365);
year = year + 1;
}
return year;
}
// Функція для обчислення початку DST (остання неділя березня)
function calculateDstStartTimestamp(year) {
const secondsInDay = 86400;
const marchDays = 31 + 28; // Дні до березня
const daysInYearBeforeMarch = isLeapYear(year) ? marchDays + 1 : marchDays;
// Початок DST -- остання неділя березня
const lastSundayMarch = daysInYearBeforeMarch + 24 - (daysInYearBeforeMarch % 7);
return lastSundayMarch * secondsInDay;
}
// Функція для обчислення кінця DST (остання неділя жовтня)
function calculateDstEndTimestamp(year) {
const secondsInDay = 86400;
const octoberDays = 31 + 30 + 31 + 30 + 31 + 30 + 31 + 31 + 30; // Дні до жовтня
const daysInYearBeforeOctober = isLeapYear(year) ? octoberDays + 1 : octoberDays;
// Кінець DST -- остання неділя жовтня
const lastSundayOctober = daysInYearBeforeOctober + 24 - (daysInYearBeforeOctober % 7);
return lastSundayOctober * secondsInDay;
}
// Функція для обчислення дати у форматі YYYY-MM-DD
function calculateDateFromTimestamp(timestampInSeconds) {
const daysInMonth = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31];
const epochYear = 1970;
const secondsInDay = 86400;
let dayssinceEpoch = Math.floor(timestampInSeconds / secondsInDay);
let year = epochYear;
// Визначаємо рік
while (dayssinceEpoch >= (isLeapYear(year) ? 366 : 365)) {
dayssinceEpoch = dayssinceEpoch - (isLeapYear(year) ? 366 : 365);
year = year + 1;
}
// Визначаємо місяць
let month = 0;
while (dayssinceEpoch >= (month === 1 && isLeapYear(year) ? 29 : daysInMonth[month])) {
dayssinceEpoch = dayssinceEpoch - (month === 1 && isLeapYear(year) ? 29 : daysInMonth[month]);
month = month + 1;
}
// Визначаємо день
const day = dayssinceEpoch + 1;
// Форматуємо дату як YYYY-MM-DD
return year + "-" + padToTwoDigits(month + 1) + "-" + padToTwoDigits(day);
}
// Функція для перевірки високосного року
function isLeapYear(year) {
return (year % 4 === 0 && year % 100 !== 0) || (year % 400 === 0);
}
// Функція для форматування числа до двох цифр
function padToTwoDigits(number) {
return (number < 10 ? "0" : "") + number;
}Так-так, шматочок вийшов великим, але він враховує усі особливості з переходами на літній та зимовий час, чого немає в багатьох інших часових поясах. Сподіваюсь, що це вам буде корисно:)
ВАЖЛИВО! Якщо в Україні перестануть переходити на літній та зимовий час, то скрипт потрібно буде переглянути.
Зміна коду та полів шаблону
Ви можете вносити інші зміни у наш шаблон і відслідковувати коректність відпрацювання в журналі помилок
Якщо ви внесли якісь зміни і зробили щось не так, то в режимі дебаг в’ю серверного гтм скоріш за все побачите помилки в консолі до вашого тегу з шаблоном.
Приклад помилки:

Це я до того, що якщо ви будете вносити будь-які зміни в схему таблиці\коді скрипта, то завжди уважно перевіряйте дані в режимі прев’ю і чи не виникне помилок з записом даних після змін.
Але бувають випадки, коли віддебажити помилку в превью не виходить і тоді “спіймати” її можна лише на реальних даних. На випадок таких змін ми врахували можливість запису даних в “запасну” таблицю, яка слугуватиме журналом помилок в BigQuery.
Тобто якщо ви внесли зміни в шаблоні, в режимі дебагу не побачили нічого підозрілого, то все одно залишається вірогідність, що з певних причин дані не будуть записані в основну таблицю.
Саме тому рекомендуємо в таких випадках завжди створювати ще одну таблицю для запису помилок.
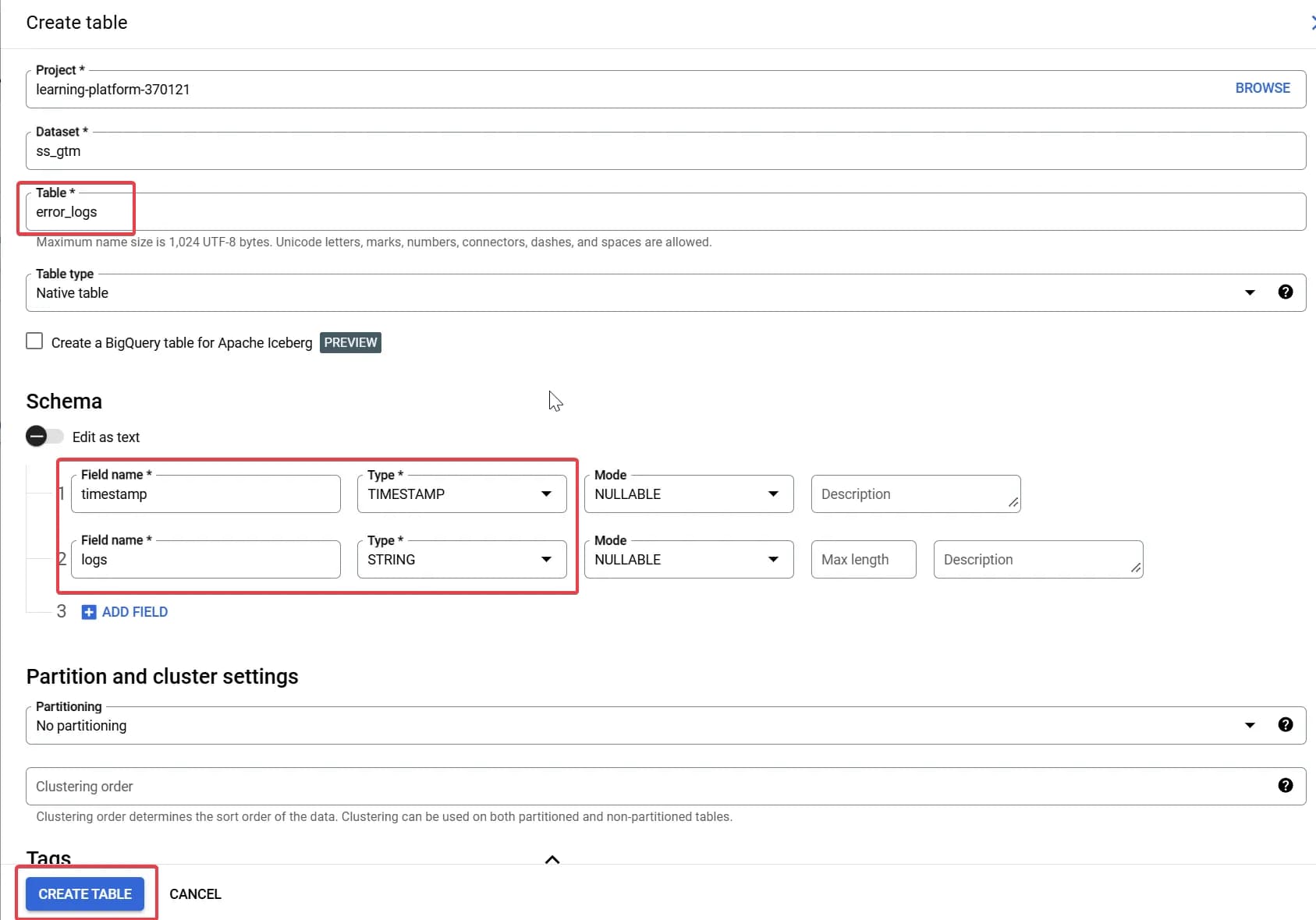
Вона повинна мати ось таку схему:
[
{
"name": "timestamp",
"type": "TIMESTAMP",
"mode": "NULLABLE"
},
{
"name": "logs",
"type": "STRING",
"mode": "NULLABLE"
}
]Важливо! З поточною логікою коду, таблицю потрібно створити в тому ж датасеті, де лежить й основна.
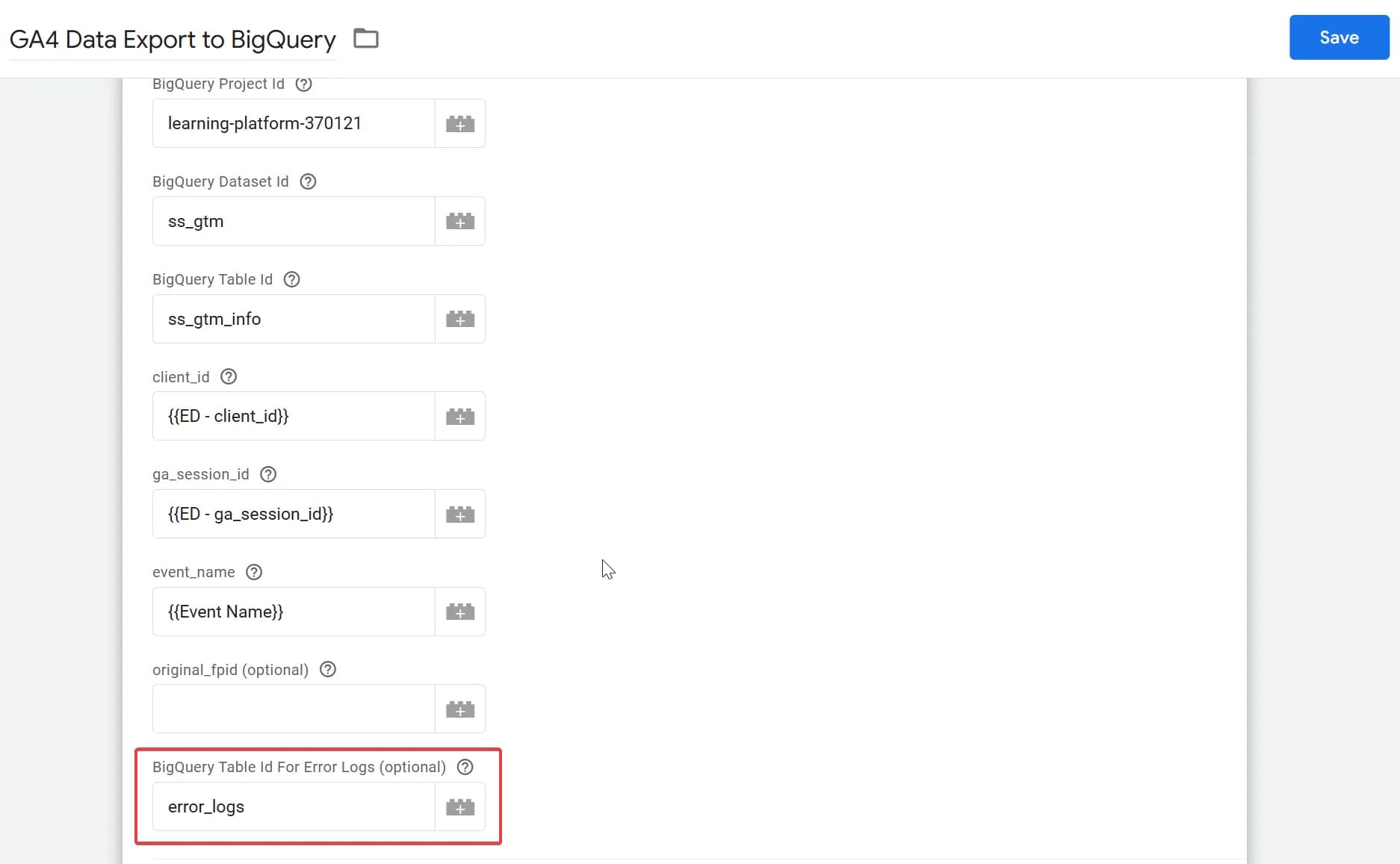
Далі потрібно вставити ID таблиці в поле тегу та зберегти:
Ці дані будуть відображатись наступним чином: ви побачите усі дані в сирому вигляді і додатково в кінці повідомлення про помилку:

Вказаний текст помилки навряд в цьому випадку вам допоможе, але у вас будуть хоча б всі дані для більш детального дослідження і пошуку причини, чому якась їхня частина не захотіла записуватись в вашу існуючу структуру. І якщо спробувати записати ці дані через API в таблицю - то можна буде побачити й детальну помилку
До речі, ці дані також, за бажанням, можна буде дописати в вашу основну таблицю, оскільки невірні дані не втрачаються.
Звісно, що на цьому ідеї для модифікацій не завершуються. Якщо на цьому етапі у вас з'явилися цікаві думки про модифікації - поділіться ними в коментарях.
Отриманий результат та робота з даними
Дані отримані напряму з Server-Side GTM у BigQuery за допомогою нашого шаблону повинні бути точнішими за дані зі стандартного експорту GA4.
Для впевненості в роботі ваших налаштувань було б добре провести звірку: взяти дані зі стандартного експорту (неважливо, яке у вас оновлення - раз на день або стрімінг) та порівняти з даними, які ви отримаєте напряму.
В результаті у вас має бути позитивна картинка - дані або співпадають з інтерфейсом або ж їх навіть більше.
На скріні нижче приклад такої звірки на одному з наших проєктів.
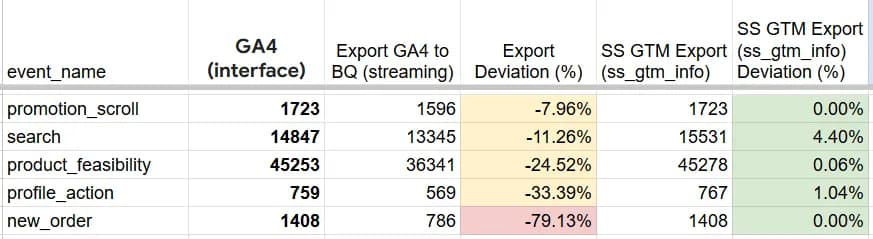
В нашу попередню табличку додалось ще два поля:
- SS GTM Export (ss_gtm_info) - дані з нашої таблички, що отримує інформацію напряму з Server-Side GTM.
- SS GTM Export (ss_gtm_info) Deviation (%) - відсоток відхилення даних з цієї ж таблички відносно інтерфейсу GA4.
В більшості випадків ми отримуємо більше даних порівняно з інтерфейсом.
Нагадаю, що нашою метою було отримати співставні дані з інтерфейсом аналітики, тому можна вважати, що цей метод чудово впорався.
Якщо ви хочете наблизити дані до вигляду як в GA4 або зробити наше рішення кращим, то ось декілька ідей і способів їх реалізації:
- Додати події first_visit, session_start
Оскільки ці події з'являються при обробці даних на стороні GA4, то в прямому експорті з Server-Side GTM ми їх не отримаємо, але їх можна дописати у таблицю за допомогою запитів.
first_visit - визначити перший наявний івент в розрізі user_pseudo_id і скопіювати з нього дані, замінивши назву івенту,
session_start - те саме, але в розрізі вже сесій (user_pseudo_id + ga_session_id)
2. Додати джерела трафіку у відповідній моделі атрибуції
Окремих полів з джерелами в нашій структурі немає, тому для визначення джерел трафіку потрібно орієнтуватися на дані в page_location та page_referrer.
А далі, в залежності від моделі атрибуції, виводити джерела в тому вигляді, який вам потрібен.
3. Ідентифікація юзера
Вище я вже описувала, що за допомогою пар оригінальних cid + fpid можна визначати юзера більш точно, ніж це робить GA4.
А також можна для деталізації додати ще ваш внутрішній user_id.
Змоделюємо ситуацію: юзер заходить на ваш сайт, ходить по сторінкам, взаємодіє з контентом і в певний момент авторизується і продовжує взаємодію. Тобто в нього спочатку був пустий user_id, а далі ми вже його ідентифікуємо. Маючи ці дані можна ще детальніше формувати контейнери на основі комбінацій з cid+ fpid +user_id:
| original_cid | original_fpid | final_cid | user_id | container_id |
|---|---|---|---|---|
12345 | - | 12345 | - | 1111 |
12345 | hash(12345) | hash(12345) | 1111 | 1111 |
23456 | hash(12345) | hash(12345) | - | 1111 |
33456 | - | 33456 | 1111 | 1111 |
- original_cid - cid з вхідного запиту
- original_fpid - fpid з вхідного запиту
- final_cid - cid, що летить в аналітику (визначає юзера по логіці GA4)
- user_id - ваш внутрішній ідентифікатор клієнта
- container_id - фінальний ідентифікатор контейнера, який визначається за допомогою додаткової обробки значень з перших двох колонок + user_id
Можна придумати ще додаткові маніпуляції, але завжди треба виходити з потреб на проєкті і доцільності таких дій.
Для себе ми підкреслили можливість отримання даних з GA4 в повному об’ємі і в тому форматі, який нам потрібен, тому для нас такі налаштування матимуть сенс не на одному проєкті.
З плюсів цього рішення:
- Отримання повних даних, на основі яких ви зможете приймати правильні рішення.
- Отримання даних в ріалтаймі - дуже важливий пункт для побудови ріалтайм репортів.
- Гнучкість та адаптивність до тієї структури, що потрібна саме вам - як то кажуть “філ фрі” і не бійтесь вносити зміни в наш шаблон і створювати щось своє. Власне, ми розписували цю статтю ще й для того, щоб ви змогли створювати .
- Вартість буде співставна зі стрімінговим експортом даних з GA4.
З мінусів:
- Потреба в пост-обробці, але, насправді, дані з GA4 також потребують пост-обробки. Інколи можна зіштовхнутись і з неточностями з боку GA4, наприклад, при визначенні джерел трафіку (детальніше про ці розбіжності писала наша колега у своїй статті), тому ми завжди використовуємо свою логіку для обробки даних з GA4.
- Це рішення потребує використання серверного тег-менеджера, тому якщо на даному етапі його у вас ще немає, це рішення буде дещо дорожчим для вас. Потрібно буде підняти серверний GTM, і це додаткові витрати, яких у вас раніше не було.
Але не треба забувати про те, що серверний GTM закриє не тільки цю задачу, але й має безліч інших переваг. Серед яких:
1. Зменшення навантаження на сторінку завдяки зменшенню JS-кодів і як результат покращення швидкості завантаження сторінки.
2. Змінна контексту для аналітичних та маркетингових cookie з third-party на first-party, а значить краща і точніша ідентифікація користувачів.
І багато іншого. Але це вже тема іншої статті, яку, до речі, вже написав мій колега.
Сподіваюсь, що я змогла вас зацікавити і ви дочитали цю статтю аж до цього речення) Якщо це так, поділіться своїми думками в коментарях. Що ви думаєте щодо цього рішення?
Коментарі
Поділися думкою та постав запитання
Завантаження коментарів...