

Поліна Мерзлікіна
Data Engineer / Data ScientistЯк перенести дані з PostgreSQL у BigQuery: Data Transfer vs Datastream
Одна з задач сучасної аналітики — зменшити кількість інтерфейсів, з якими вам потрібно працювати. Іншими словами, замість десятків різних сервісів зібрати все в один зрозумілий дашборд. А побудові такого дашборду зазвичай передує збір даних з різних систем (БД, рекламних кабінетів, CRM) в одному місці. Якщо таким місцем збереження даних у вас є BigQuery, то ця стаття для вас.
Загалом, способів передачі даних з одного місця в інше існує багато, в цьому матеріалі я розгляну найбільш інтегровані в Google Cloud: два нативні сервіси Data Transfer і Datastream. Як приклад джерела візьмемо PostgreSQL, проте якщо його у вас немає, стаття все одно може бути корисною: обидва сервіси підтримують й інші джерела (детальніше розбираю нижче тут і тут), а принципи вибору між пакетною передачею і потоковою реплікацією універсальні.
Data Transfer і Datastream — нативна частина Google Cloud: не треба підключати сторонні інструменти чи виходити за межі екосистеми Google Cloud. І обидва зараз активно розвиваються, що і стало приводом описати їх детальніше.
Стаття є практичним покроковим посібником і буде корисною дата-інженерам та аналітикам, які люблять заглиблюватись на технічний рівень і мають досвід роботи з Google Cloud. Знадобиться також доступ до налаштувань PostgreSQL або колаборація з тим, хто його адмініструє, без цього частину кроків не пройти.
Усі розрахунки та скріншоти в статті актуальні на квітень 2026 року. Для власних розрахунків щодо ціни сервісів звіряйтеся з актуальною документацією.
Нижче розберемо обмеження, налаштування, порівняння Data Transfer і Datastream — повний план:
Що визначити перед вибором інструмента
Перш ніж обирати інструмент вивантаження даних (з описаних в цій статті чи будь-який інший), потрібно визначити вимоги до передачі даних.
Наступні питання допоможуть як з вибором інструменту, так і з оцінкою вартості, і прояснять, які вимоги для вас критичні:
- Який обсяг історичних даних потрібно завантажити в BigQuery?
- Як часто мають оновлюватись дані в BigQuery? Чи потрібне оновлення в реальному часі?
- Який обсяг даних змінюється або створюється за певний період часу? (відносно бажаної частоти оновлення)
Ось як два сервіси співвідносяться за ключовими критеріями:
Верхньорівневе порівняння Data Transfer Service і Datastream
| Критерій | Data Transfer | Datastream |
|---|---|---|
Принцип роботи | Планові пакетні передачі за розкладом (мін. 15 хв) | Безперервна потокова реплікація. |
Мінімальна затримка даних | Від 15 хвилин. | Від кількох секунд. |
Складність налаштування | Низька, достатньо логін/пароль до PostgreSQL і мережевий доступ. | Середня, потрібно налаштувати logical replication, publication, replication slot, connection profiles. |
Підготовка PostgreSQL | Створити користувача з SELECT доступом + налаштувати мережевий доступ до PostgreSQL | Залежить від хостингу БД, але загально увімкнути WAL, створити publication, replication slot, користувача з правами реплікації. |
Write modes | Full (перезапис). | Merge (синхронізація) або Append only (історія змін). |
Вартість (модель) | За слот-години роботи конектора (передбачувано, прив'язано до часу запуску). | Дві компоненти — (1) GiB переданих змін, (2) BigQuery compute для merge-операцій, який залежить від розміру таблиць і частоти merge (max_staleness). Друга компонента може домінувати для великих таблиць. |
Передбачуваність вартості | Висока (відома кількість запусків × відомий час). | Низька — три драйвери одночасно: обсяг змін, розмір таблиці, max_staleness. |
Найкраще підходить для |
|
|
Перш ніж переходити до налаштувань, кілька слів про дані, на яких я тестувала обидва сервіси.
Тестовий датасет для прикладів
Щоб стаття була дійсно практичною і відтворюваною, як приклад я взяла публічний датасет Brazilian E-Commerce від Olist. Усі цифри і скріншоти в статті — з тестування на цьому датасеті.
Це реальні анонімізовані дані ~100 тис. замовлень з бразильських маркетплейсів за 2016–2018 роки (9 таблиць: замовлення, товари, оплати, відгуки, геолокація тощо).
Важливо мати на увазі, що дані в BigQuery займатимуть інший обсяг, ніж у PostgreSQL — через різницю у стисненні та моделі зберігання.
Найкраще завантажити якийсь тестовий шматок ваших даних в BigQuery, щоб зрозуміти, яке співвідношення розмірів буде у вашому випадку.
Скільки займають дані в БД і BigQuery для цього датасету:
| PostgreSQL | BigQuery Logical storage |
|---|---|
147.32 MB | 111.89 MB |
Як налаштувати Data Transfer Service для вивантаження PostgreSQL в BigQuery
Data Transfer Service створено для автоматизації переміщення даних у BigQuery за розкладом. Після налаштування передачі дані завантажуються автоматично на заданій регулярній основі.
На відміну від Datastream, він майже не вимагає підготовки на стороні PostgreSQL — достатньо створити користувача з правами SELECT.
Крім PostgreSQL, сервіс підтримує і інші джерела, але принцип завжди однаковий: передача з якоїсь системи → BigQuery.
Джерела даних, які підтримує Data Transfer Service

Далі розглянемо обмеження, налаштування, вартість та перевірку роботи.
Обмеження Data Transfer для PostgreSQL
- Кількість одночасних передач обмежена пропускною здатністю вашої БД (кількістю одночасних з'єднань, які вона витримує).
- У межах однієї конфігурації передачі виконуються послідовно: якщо попередній запуск не завершився до старту наступного — наступний пропускається, зважайте на це при виборі інтервалів запуску.
- Для швидкої та надійної роботи документація рекомендує для таблиць мати первинні ключі або індексовані стовпці. Це дозволяє передавати дані паралельно і швидше. Без ключів або індексів таблиця не може містити більше 2 мільйонів записів для передачі даних.
- Деякі типи PostgreSQL (наприклад, numeric без precision) перетворюються на STRING у BigQuery. Зверніть увагу на мапінг типів в документації.
Передумови
- IAM-роль: якщо у вас немає повного доступу до Google Cloud проєкту (Owner), вашій пошті потрібна роль BigQuery Admin (roles/bigquery.admin).
- Окремий користувач в PostgreSQL з відповідними правами SELECT на потрібні таблиці.
- Мережевий доступ: PostgreSQL має бути доступний “ззовні”. Якщо ваш PostgreSQL не має публічного IP (наприклад, знаходиться в приватній мережі або за фаєрволом), можуть бути потрібні додаткові налаштування network attachment.
Покрокове налаштування Data Transfer
Пройдімося кроками налаштування вивантаження (лишаю також посилання на інструкцію від Google):
- Перейдіть в вашому Google Cloud на сторінку сервісу Data Transfer і оберіть “+ Create transfer”, в Source type оберіть PostgreSQL.

2. Введіть усі необхідні дані для підключення до БД.
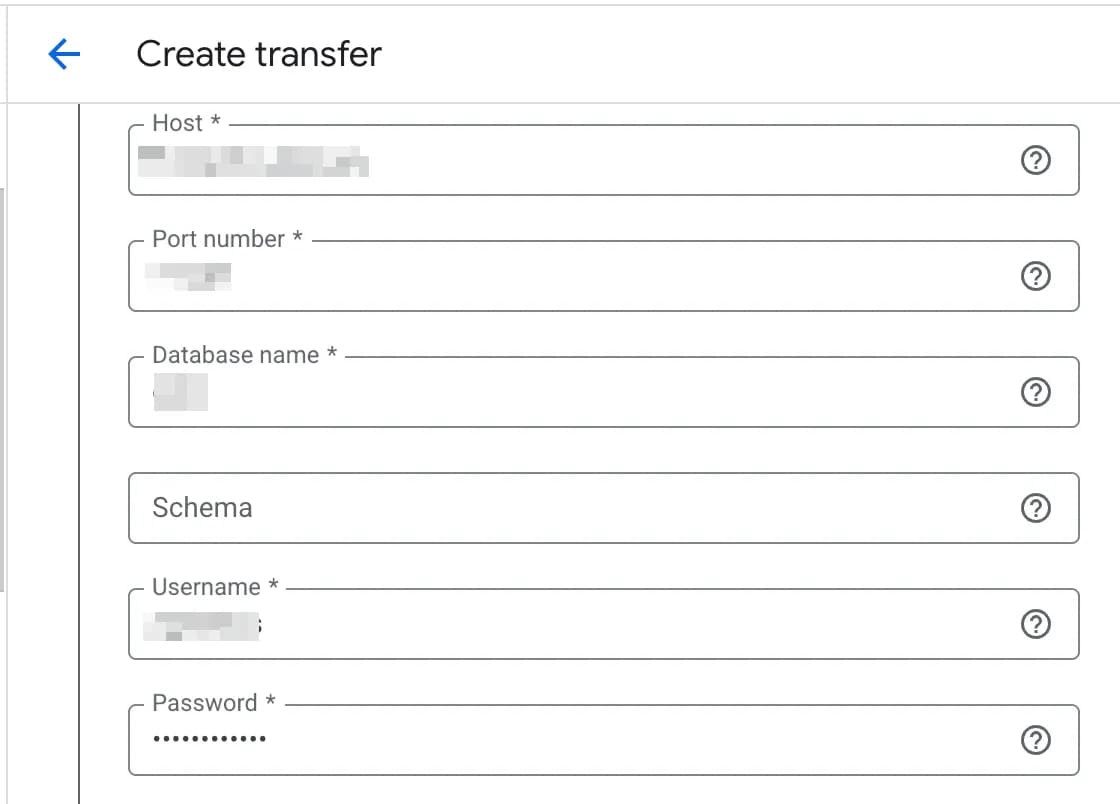
3. Оберіть TLS mode.
TLS mode — це налаштування рівня захисту з'єднання між Data Transfer і вашою базою PostgreSQL. По суті, він визначає дві речі: шифрується трафік чи ні, і перевіряється ідентичність сервера чи ні.
Конектор підтримує чотири режими TLS для шифрування з'єднання:
- Encrypt data, and verify CA and host name — найбезпечніший варіант. Шифрує дані та перевіряє і сертифікат, і hostname сервера. Потрібен TLS-сертифікат, підписаний довіреним CA, а hostname сервера має збігатися з CN або SAN у сертифікаті. При використанні приватного CA — потрібно надати повний ланцюжок довіри (сертифікат сервера + проміжні + кореневий CA).
- Encrypt data, and verify CA only — шифрує дані та перевіряє сертифікат, але не hostname. Ті самі вимоги до сертифіката, що й вище, але без необхідності налаштовувати DNS/hostname. Підходить, якщо у вас немає контролю над hostname або він не збігається з сертифікатом.
- Encryption only — шифрує дані, але не перевіряє ні сертифікат, ні hostname. Достатньо увімкнути TLS на стороні PostgreSQL (ssl = on в postgresql.conf), навіть self-signed сертифікат підійде. Google рекомендує цей варіант для роботи через приватні VPC.
- No encryption or verification — без шифрування, дані передаються відкритим текстом. Нічого додатково налаштовувати не потрібно, але в
pg_hba.confмають бути дозволені не-SSL з'єднання. Тільки для тестування в ізольованому середовищі.

4. Оберіть Ingestion type:
- Full — кожен запуск перезаписує всі дані з таблиць повністю. Принцип дії простий, але може витрачати багато ресурсів для великих таблиць та довго відпрацьовувати.
- Incremental (Preview) — має Append та Upsert підрежими, за документацією, цей режим завантажує лише змінені дані.

Incremental опція на момент написання статті знаходиться в статусі Preview. У моїх тестах налаштувати її не вдалося — UI не давав вибрати таблиці. Тому в цій статті ми її детально не розглядаємо, але після виходу з Preview це буде варта уваги опція.
5. Оберіть таблиці для вивантаження в полі “PostgreSQL objects to transfer”, можна або ввести в текстовому полі у форматі {database}/{schema}/{table}, або вибрати через кнопку Browse, чекбокси стають доступними після розкриття згорнутих списків. Якщо у вас при натисканні на Browse видає помилки, перевірте всю інформацію про з‘єднання з PostgreSQL.

6. Оберіть результуючий датасет.
7. Оберіть бажаний розклад запусків, збережіть створену конфігурацію.
Мінімальний інтервал для PostgreSQL становить 15 хвилин (але для деяких інших джерел, наприклад, Google Ads, мінімальний інтервал буде іншим), також є опція On demand (На вимогу), якщо потрібен лише запуск вручну без розкладу (наприклад, для одноразової міграції).
Майте на увазі, що передача даних створюватиме додаткове навантаження на вашу базу, тому оптимально робити запуски не в піковий для вашого бізнесу час (наприклад, вночі для щоденних вивантажень).

Як перевірити роботу Data Transfer service
Щоб перевірити відпрацювання створеної вами передачі даних, перейдіть в розділ Run history, він містить всю історію і логи запусків.
Якщо були помилки в запусках, їх причину можна детальніше подивитись в полі View details.

Скільки коштує Data Transfer
Далі буде описана вартість тільки за сервіси Google Cloud; залежно від того, де розміщені ваші дані (AWS, власний сервер і т.д.), можуть бути додаткові витрати в цих системах, наприклад, за вихідний трафік.
- Transfer Orchestration: ресурси на обслуговування роботи конектора.
Не всі конектори тарифікуються однаково. Безкоштовно працюють: Конектори Google-екосистеми та сховищ даних (Google Ads, GA4, Cloud Storage, Amazon S3, Azure Blob Storage та інші) та конектори в статусі Preview — Google почне нараховувати плату після їх переходу в general availability.
PostgreSQL входить до Paid connectors (разом з MySQL, Oracle, Salesforce, ServiceNow, Facebook Ads, SFMC) і тарифікується за фактичне використання в слот-годинах.
Слот-година — одиниця обчислювальної потужності BigQuery (віртуальний CPU). Один слот, що працював одну годину = одна слот-година.

Вартість залежить від регіону, для розрахунку вартості оберіть ваш регіон серед переліку.

Документація радить для оцінки витрат використовувати орієнтир до 20 слот-годин на кожну годину роботи передачі, не вказано, за яку кількість даних, тому реальну картину для ваших даних можна подивитись виключно під час тестового вивантаження.
Щоб прикинути вартість на місяць, потрібно помножити кількість слот-годин на частоту запусків + врахувати майбутнє збільшення даних.
Для датасету, згаданого в цій статті, разова передача даних з налаштуваннями і даними, описаними вище, зайняла приблизно 17 слот-хвилин (≈0.28 слот-години) (може також впливати якість і швидкість з‘єднання з БД).
Якщо припустити, що передача даних працюватиме раз на день в регіоні europe-west1 за $0.066/слот-година, вартість Transfer Orchestration становитиме приблизно разів_на_місяць × слот-годин_на_запуск × ціна_за_слот-годину = 30 × 0.28 × $0.066 = $0.56 (без врахування збільшення майбутніх даних), тобто навіть з запасом для бази обсягом 200МБ вкладемось в $1.
- Data Loading & Processing: ресурси на завантаження та злиття даних у цільову таблицю. Вартість цієї складової залежить від типу операції:
- Load (завантаження) — безкоштовно для BigQuery Native Tables. Це стандартні load jobs, які відбуваються при кожній передачі даних.
- Merge (злиття) — тарифікується за стандартними BigQuery rates. Merge відбувається, коли використовується Incremental ingestion з Upsert write mode — тобто коли дані не просто додаються, а порівнюються з існуючими і оновлюються.
Простіше кажучи, якщо ви використовуєте Full ingestion, то платите лише за Transfer Orchestration. Якщо Incremental з Upsert, додається ще вартість merge-операцій за стандартними тарифами BigQuery.
Зручно подивитись витрати на Data Transfer можна в Billing Report -> Labels: key=goog-bq-feature-type, value=DATA_TRANSFER_SERVICE, але треба враховувати, що для оновлення billing report інформації потрібно близько доби і вона не буде доступна в реальному часі.

Як налаштувати Datastream для вивантаження PostgreSQL в BigQuery
Якщо Data Transfer — це планові відправки, то Datastream — це безперервний конвеєр.
Datastream — це безсерверний сервіс Google Cloud для реплікації даних у реальному часі через механізм CDC (Change Data Capture). На відміну від Data Transfer, який працює за розкладом і завантажує дані "порціями", Datastream безперервно відстежує зміни у базі даних і передає їх у BigQuery з мінімальною затримкою.
Як джерело, Datastream підтримує й інші системи (MySQL, Oracle, SQL Server, MongoDB, Spanner, Salesforce), а крім BigQuery може записувати ще й у Cloud Storage. Налаштування Datastream складніше за Data Transfer — потрібно підготувати базу даних та створити connection profiles. Далі покажу крок за кроком.
Джерела даних, які підтримує Datastream

Має два режими роботи (і різну вартість):
- CDC (Change Data Capture) — у реальному часі відстежує та передає поточні зміни з джерела: INSERT, UPDATE, DELETE.
- Backfill (початкове заповнення) — створює історичну копію даних, які вже існують у таблиці. Відбувається автоматично при створенні стріму або може бути ініційований вручну. Якщо у вас уже є вивантаження історичних даних, в документації є додаткова інформація про використання вже існуючих таблиць.
Під час вивантаження Datastream додає в BigQuery таблиці системний стовпець datastream_metadata, його вміст залежить від обраного write mode (merge / append-only) і наявності primary key (PK), наприклад, для merge mode.

У append-only режимі додаються поля CHANGE_TYPE (INSERT / UPDATE-INSERT / UPDATE-DELETE / DELETE), CHANGE_SEQUENCE_NUMBER і SORT_KEYS — без них неможливо коректно відновити порядок і тип змін з історії. А для таблиць без PK у merge-режимі додається поле IS_DELETED, і таблиця автоматично працює як append-only.
Обмеження Datastream для PostgreSQL
- Для PostgreSQL як source (перераховані лише основні обмеження)
- Один стрім підтримує до 10 000 таблиць.
- Таблиці без primary key повинні мати налаштований REPLICA IDENTITY, інакше реплікуються лише INSERT-и.
- Таблиці з primary key не можуть мати REPLICA IDENTITY FULL або NOTHING — тільки DEFAULT.
- При REPLICA IDENTITY FULL на таблицях з більш ніж 16 стовпцями стрім не запуститься (перевищує ліміт BigQuery на primary keys у MERGE-операціях).
- Таблиці з більш ніж 500 млн рядків не можуть бути backfill-нуті без унікального B-tree індексу з не-nullable стовпцями.
- Не підтримуються таблиці з Row-Level Security.
- Read replica як джерело не підтримується.
- Зміни в схемі можуть не відстежитись автоматично (видалення колонок, зміна типу даних колонки, зміна порядку колонок).
- Після мажорного апгрейду PostgreSQL стрім може перестати працювати і потрібно перестворити replication slot.
- Для BigQuery як destination
- Максимальний розмір однієї події — 20 MB. Подія — це одна зміна одного рядка (INSERT/UPDATE/DELETE). Це з запасом для типових таблиць, але може стати проблемою для рядків з великими TEXT, JSON або BYTEA колонками.
- Primary key таблиці має бути одного з підтримуваних типів (DATE, BOOL, INT64, NUMERIC, STRING, TIMESTAMP та інші) — таблиці з FLOAT або REAL primary key не реплікуються.
- Не можна додати або прибрати primary key у вже реплікованій таблиці без звернення до Google Support.
- BigQuery не підтримує більше чотирьох clustering columns. Якщо primary key складається з більш ніж 4 стовпців, Datastream все одно реплікує всі PK-колонки, але як clustering columns візьме лише перші чотири.
Передумови
На відміну від Data Transfer, де достатньо вказати логін/пароль до PostgreSQL, Datastream потребує більшої підготовки на стороні бази даних. Детальні інструкції залежать від того, де хоститься ваш PostgreSQL. Налаштування для конкретних типів / розміщень PostgreSQL можна попередньо подивитись в документації, або знайти ці інструкції безпосередньо в інтерфейсі налаштування стріма.
Покрокове налаштування Datastream
Процес налаштування сервісу Datastream складається з таких частин:
- налаштування стріма.
- створення двох профілів з‘єднання (connection profiles) для джерела (PostgreSQL) і для призначення (BigQuery), можуть бути як новостворені при створенні стріма, так і вже раніше налаштовані.
Будьте уважні при виборі регіону для налаштувань профілів з‘єднання, бо якщо регіони не будуть сходитись, стрім не створиться.
- Для налаштування стріма знайдіть Datastream у Google Cloud (в пошуку введіть "datastream").

2. У відкритому сервісі натисніть Create stream.

3. Відкриється сторінка налаштувань стріма:
- 3.1 Заповніть базові значення:
- назва стріму.
- регіон (рекомендується той самий, де буде BigQuery датасет).
- Source type = PostgreSQL, Destination type = BigQuery.

- 3.2 На цій же сторінці будуть доступні інструкції з додаткової конфігурації PostgreSQL, щоб побачити їх натисніть Open.

- 3.3 Оберіть тип вашої PostgreSQL (Cloud SQL, Self-hosted, RDS, Aurora, AlloyDB) — для кожного типу інтерфейс покаже відповідну інструкцію з підготовки БД.

Наприклад для Self-hosted PostgreSQL налаштування будуть такі (перед виконанням SQL-команд обов‘язково перевірте, чи ви обрали правильну database в PostgreSQL):

- 3.4 Після конфігурації вашої PostgreSQL натисніть Continue, щоб перейти до наступного кроку.

4. Створіть або оберіть профіль з'єднання (connection profile) для джерела (в нашому випадку PostgreSQL). Якщо ви вже маєте створений раніше, оберіть його зі списку і переходьте до пункту 5 цієї інструкції.
- 4.1 Для створення нового, натисніть Create connection profile.

- 4.2 Заповніть необхідні поля.
- Connection profile name — довільна назва (до 60 символів).
- Connection profile ID — автоматично генерується, але можна змінити (тільки малі літери, цифри, дефіси).
- Region — оберіть той самий регіон, де створюватимете стрім.
Якщо регіони не збігаються, стрім не створиться. Вибір регіону незворотний після збереження. Це важливо, якщо ви використовуєте вже створений раніше connection profile.

- 4.3 Заповніть параметри з‘єднання:
- Hostname or IP — адреса вашого PostgreSQL сервера.
- Port — зазвичай 5432.
- Username — користувач з правами реплікації (створений на етапі передумов).
- Password — можна зберегти в Google Secret Manager (рекомендовано) або ввести вручну.
- Database — назва бази даних для реплікації.

- 4.4 Оберіть тип шифрування:
- None — без шифрування (не рекомендовано).
- Server only — шифрує з'єднання та перевіряє сертифікат сервера. Потребує Source CA certificate (сертифікат від Certificate Authority у форматі PEM і Server certificate hostname — hostname сервера для валідації SSL-сертифіката).
- Server client — шифрує з'єднання та автентифікує обидві сторони (найбезпечніший варіант). Потребує три сертифікати у форматі PEM:
- Source CA certificate — сертифікат від Certificate Authority для перевірки сервера,
- Source client certificate — сертифікат, який Datastream використовує для автентифікації на сервері,
- Source private key — приватний ключ до клієнтського сертифіката (незашифрований, PKCS#1 або PKCS#8).

- 4.5 Оберіть connectivity method (як Datastream підключатиметься до PostgreSQL):
- IP allowlisting — доступ із зовнішніх мереж, не захищений (найпростіший варіант для тестування).
- Forward-SSH tunnel — доступ із зовнішніх мереж через зашифрований SSH-тунель.
- Private connectivity — доступ через приватну мережу Google (VPN або Interconnect) — найбезпечніший варіант для production.

- 4.6 Після заповнення всіх налаштувань, запустіть тест підключення (у випадку помилок буде вказана їх причина). При успішному тесті переходьте далі.

5. Налаштуйте джерело (Configure source) PostgreSQL.
- 5.1 У розділі Replication properties вкажіть назви об'єктів, створених на етапі підготовки PostgreSQL:
- Replication slot name — назва replication slot, яку ви створили в PostgreSQL командою
SELECT
PG_CREATE_LOGICAL_REPLICATION_SLOT(...)
Сервер використовує цей slot для відправки змін до Datastream. - Publication name — назва publication, створеної в PostgreSQL командою
CREATE PUBLICATION.... Publication визначає, які таблиці будуть реплікуватися цим стрімом.
- Replication slot name — назва replication slot, яку ви створили в PostgreSQL командою

- 5.2 У Select objects to include оберіть потрібні таблиці для реплікації:
- All tables from all schemas — усі існуючі таблиці з усіх схем, включно з таблицями, які будуть додані в майбутньому.
- Specific schemas and tables — вибрати конкретні схеми та таблиці зі списку.
- Custom — вручну задати список схем і таблиць.

- 5.3 Show advanced options (необов'язково):

- Choose backfill mode (початкове заповнення) — як заповнювати історичні дані:
- Automatic — Datastream автоматично завантажить всі існуючі дані при запуску стріму.
- Manual — Datastream передаватиме лише нові зміни, історичні дані потрібно завантажити окремо.

- Maximum concurrent backfill connections — скільки паралельних з'єднань використовувати для backfill (за замовчуванням 16). Більше з'єднань = швидше завантаження, але більше навантаження на базу.
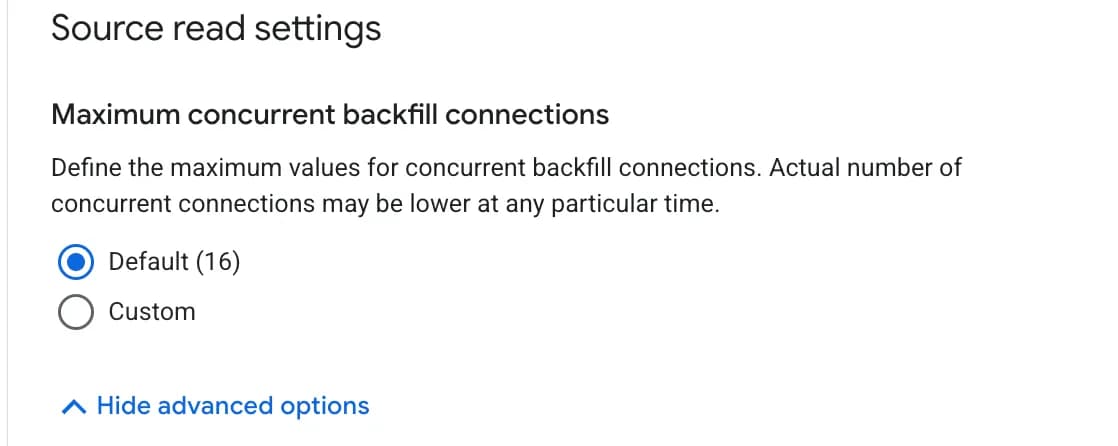
- 5.4 Після заповнення натисніть Continue.
6. Створіть або оберіть профіль з‘єднання (connection profile) для зберігання отриманих даних в BigQuery. Якщо ви вже маєте створений раніше, оберіть його зі списку і переходьте до пункту 7 цієї інструкції.
- 6.1 Для створення нового, натисніть Create connection profile.

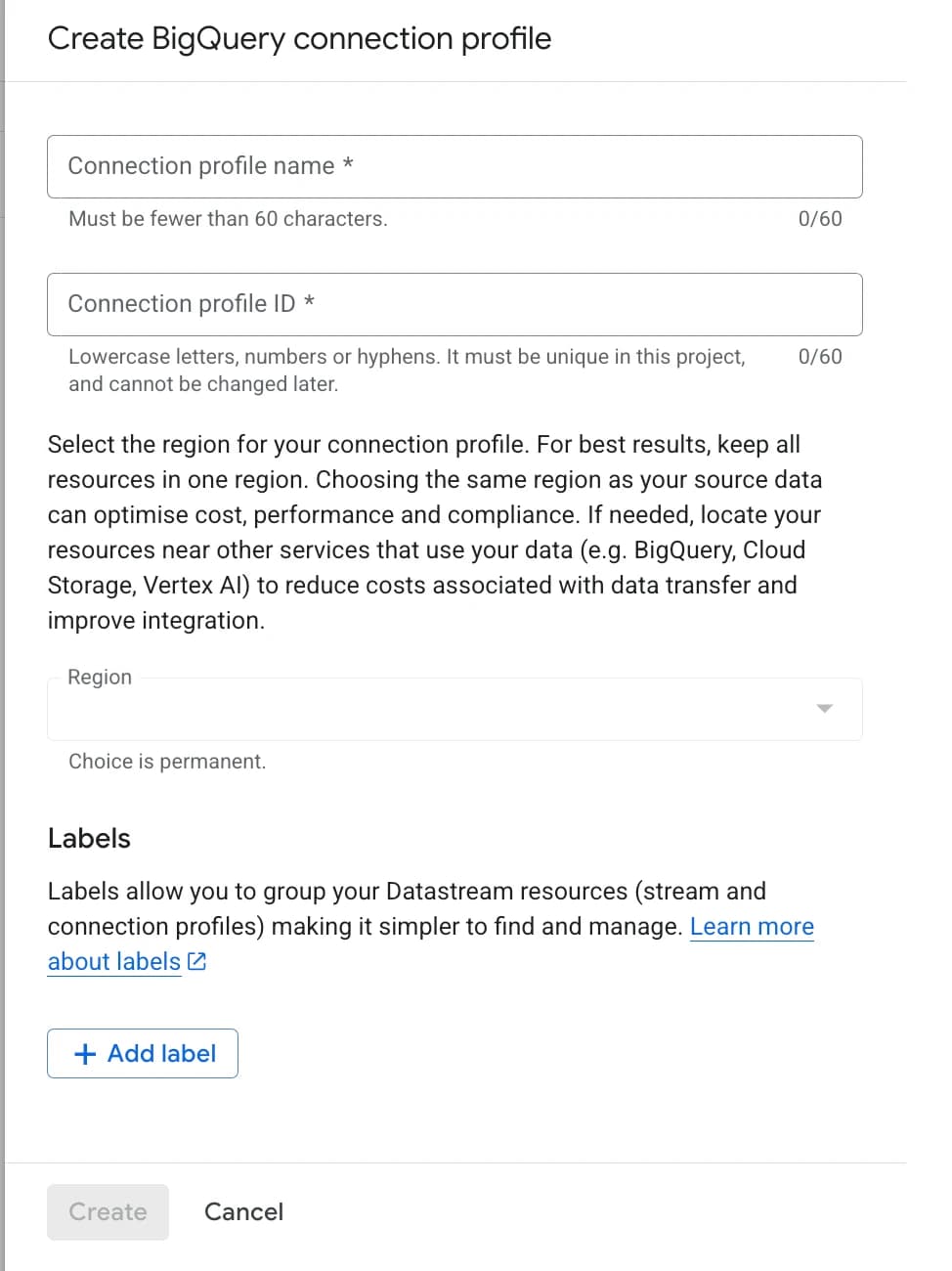
- 6.2 Заповніть необхідні поля:
- Connection profile name — довільна назва (до 60 символів).
- Connection profile ID — автоматично генерується, але можна змінити (тільки малі літери, цифри, дефіси).
- Region — має бути той самий регіон, де створюєте стрім.
Якщо регіони не збігаються, стрім не створиться. Вибір регіону незворотний після збереження. Це важливо, якщо ви використовуєте вже створений раніше connection profile.
- 6.3 Натисніть Continue.
7. Налаштування принципу запису в BigQuery:
- 7.1 Оберіть, як створюватимуться відповідні датасети в BigQuery:
Dataset for each schema — кожна схема PostgreSQL стане окремим датасетом у BigQuery (наприклад, схема sales → датасет sales). Зручно, коли у вас чітко розділені схеми за функціоналом.
Single dataset for all schemas — усі таблиці з усіх схем потраплять в один датасет, а назви таблиць складатимуться як schema_table (наприклад, sales_orders). Простіше для невеликих баз.

Dataset location (регіон датасету)
Оберіть регіон, де зберігатимуться дані в BigQuery. Рекомендується той самий регіон, де створений стрім.
Префікси для назв (опційно)
Необов'язково, але корисно: можна додати префікс до назв датасетів, щоб відрізняти їх від інших датасетів у BigQuery. Префікс додається на початок назви датасету.
- 7.2 Оберіть Stream write mode:
- Merge — BigQuery буде синхронізований з джерелом: нові рядки додаються, існуючі оновлюються, видалені видаляються. Підходить, коли потрібна актуальна копія бази. Працює лише для таблиць з primary key, таблиці без PK автоматично працюють в append-only режимі.
- Append only — кожна зміна записується як окремий рядок. Зберігається повна історія змін.

- 7.3 Оберіть data staleness limit — визначає, наскільки "свіжими" будуть дані в BigQuery, і означає, що BigQuery гарантує застосування накопичених змін з джерела принаймні раз на цей інтервал (в документації цей параметр називається
max_staleness).
Як це працює:
Datastream постійно стрімить зміни у write-optimized storage таблиці BigQuery (умовно "буфер змін"), а BigQuery періодично запускає background apply job, який зливає (merge) ці зміни з основною (baseline) таблицею.
Що це означає для ваших запитів:
Якщо запит відбувається в межахmax_stalenessпісля останнього merge — BigQuery повертає версію таблиці станом на цей merge (тобто дані можуть бути на кілька хвилин старішими за реальність, але запит дешевий і швидкий, бо читається вже злита таблиця).
Якщо запит виходить за межіmax_staleness— BigQuery змушений зробити runtime merge на льоту: склеює основну таблицю з накопиченими змінами під час вашого запиту. Дані актуальні, але запит повільніший і дорожчий.
Особливий випадок, колиmax_stalenessдорівнює 0 (опція "0 seconds" у Datastream): кожен запит виконує runtime merge, бо буфер змін ніколи не вважається застарілим заздалегідь, це дає найсвіжіші дані, але витікає в найдорожчі запити.
Резюмуючи, менше значенняmax_stalenessдозволяє отримати свіжіші дані, але більше background apply jobs (або runtime merges) — це вища вартість. Google надає спеціальну формулу для визначення max_staleness.
Можлива частота оновлення: від 0 секунд до 1 дня.

8. В кінці налаштувань у вас буде екран з усіма вашими введеними значеннями та можливістю провалідувати підключення на помилки кнопкою Run validation.

Якщо є проблеми з налаштуваннями, їх можна побачити в переліку та отримати більш детальний опис до кожної проблеми.

Як перевірити відпрацювання Datastream
Логи мають інакший принцип, ніж у Data Transfer, на сторінці стрімів видно статус стріму (Running / Paused) і кнопку View logs, яка в процесі вивантаження нічого не показує.

Більше корисної інформації можна побачити в дашборді стріму, який відкривається після кліку на його назву. Там можна побачити статус backfill, кількість оброблених подій і графік Data freshness — наскільки свіжі дані зараз у BigQuery відносно джерела.

Скільки коштує Datastream
Далі буде описана вартість тільки за сервіси Google Cloud; аналогічно до Data Transfer, можуть бути додаткові витрати на стороні джерела (наприклад, AWS egress costs).
- Datastream CDC — плата за безперервну передачу змін, тарифікується за об'єм переданих даних (GiB). Ціна залежить від регіону та об'єму, має градуйовану ціну зі знижками при більших об'ємах.

- Datastream Backfill (початкове заповнення історичних даних) — тарифікується окремо від CDC. Перші 500 GiB на місяць — безкоштовно, далі тарифікується. Це означає, що для невеликих датасетів початкове заповнення буде безкоштовним.

- BigQuery CDC Processing — вартість обчислювальних операцій, які BigQuery виконує для синхронізації даних. Це найнепередбачуваніша складова вартості, на яку варто звернути увагу окремо. Включає три типи jobs:
- Background apply jobs — фонові merge-операції, які застосовують накопичені зміни в межах
max_staleness. Виконуються регулярно і читають всю базову таблицю (не використовують партиціонування і кластеризацію). - Query jobs — звичайні запити в межах
max_staleness, читають baseline-таблицю з підтримкою партиціонування і кластеризації. - Runtime merge jobs — запити поза вікном
max_staleness, які змушені робити merge на льоту. Теж сканують всю таблицю.
На що це впливає в реальних грошах: - Низький
max_stalenessна великій таблиці може коштувати дорого — кожна background apply job читатиме всю таблицю. Рекомендація Google по вибору max_staleness. - За замовчуванням ці операції тарифікуються за on-demand моделлю ($6.25 / 1 TiB processed).
- Background apply jobs — фонові merge-операції, які застосовують накопичені зміни в межах
- BigQuery Storage — стандартна вартість зберігання даних у BigQuery (аналогічно до Data Transfer); яким би способом ви не складали дані, ця сума буде завжди однаковою.
Далі буде наведено орієнтовний розрахунок. Реальні цифри залежать від кількості колонок у таблиці, типів даних, патерну змін (UPDATE проти INSERT), кількості primary keys і складності схеми. Перед production-запуском обов'язково тестуйте на ваших реальних даних з моніторингом billing-репорту.
Розрахуємо повну вартість для нашого тестового датасету (~150 MB, 9 таблиць). Припустимо, у джерелі генерується 10 MB змін на день (≈300 MB/місяць).
- Datastream Backfill: 150 MB — у межах безкоштовних 500 GiB → $0.
- Datastream CDC: 300 MB ≈ 0.3 GiB × $2.202/GiB = ~$0.66/місяць (ціна для europe-west1).
- BigQuery CDC processing: background apply jobs читають всю baseline-таблицю при кожному merge. Припустимо, max_staleness = 15 хв → 96 запусків/день. Кожен запуск сканує таблицю та буфер змін з overhead на merge, реальний обсяг processed data може бути у 1.5-3 рази більший за саму таблицю.
Для нашої таблиці 0.15 GB — це ~96 запусків × 30 днів × 0.3 GB ≈ 864 GB processed/місяць ≈ 0.84 TB × $6.25 = ~$5.25/місяць на on-demand BigQuery. - BigQuery Storage: ~0.15 GB × $0.02/GB = $0.003/місяць (далеко в межах free tier 10 GB).
Разом для маленького датасету: ~$6/місяць.
Ключова деталь: складова “3. BigQuery CDC processing” масштабується з розміром таблиці і частотою merge.
То що обрати?
Якщо після цього огляду вам захотілось спробувати — починайте з тестового шматка реальних даних.
Коротке правило вибору:
- дані оновлюються раз на день або рідше → Data Transfer.
- таблиці маленькі або середні (до кількох GB), оновлення раз на 15-60 хв влаштовує → Data Transfer.
- потрібен real-time або близько до нього → Datastream.
- велика таблиця з багатьма дрібними змінами + потрібна свіжість у годинах, не днях → Datastream (Data Transfer тут програє через постійну повну перезаливку).
- потрібна історія змін → Datastream в append-only режимі.
- не впевнені → починайте з Data Transfer: простіше налаштувати, легше замінити, передбачуваніша вартість, і Incremental mode після виходу з Preview з часом може закрити більшість сценаріїв.
Варто також подивитись на вартість зберігання в BigQuery окремо, бо вона додається до вартості обох інструментів і може суттєво вплинути на підсумкову цифру.
І варто мати на увазі, що обидва сервіси зараз активно розвиваються, наприклад, Incremental mode в Data Transfer все ще в Preview, але коли вийде з нього, може суттєво змінити підхід до вибору між цими інструментами.
Якщо потрібна допомога з налаштуванням під ваш випадок — або задача ширша, ніж просто синхронізувати дві бази (збір даних з рекламних систем, CRM чи кількох джерел одразу) — наша команда допоможе побудувати дата-пайплайн і обрати оптимальне рішення. Надішліть заявку, заповнивши форму.
Коментарі
Поділися думкою та постав запитання
Завантаження коментарів...