

Євгенія Ярушина
Тимлід аналітичної командиШвидка економія витрат на зберіганні даних у BigQuery
Кому буде корисна ця стаття
Якщо ви працюєте з BigQuery, ця стаття точно для вас. Вона допоможе розібратися, звідки беруться витрати за зберігання і як зменшити їх буквально в кілька кліків.
Матеріал особливо буде корисний, якщо:
- Ви використовуєте BigQuery для аналітики чи зберігання даних проєкту, отримуєте рахунки від Google Cloud, але не до кінця розумієте, за що саме знімають кошти.
- Проєкт ще маленький і ваші дані влазять у безкоштовні місячні ліміти або ви тільки створили порожній проєкт. Ця стаття допоможе уникнути непотрібних витрат у майбутньому.
- У вас є розуміння, за що ви платите гроші, але шукаєте рішення для зменшення рахунків.
Кожен проєкт починається з малого: перших даних, перших таблиць. Але коли бізнес росте — ростуть і дані, і невдовзі в акаунті з’являються щомісячні витрати на BigQuery.
Коли ми працюємо з даними у BigQuery як аналітики, то фактично маємо три основні процеси:
- зберігання,
- обробка,
- запис даних.
Платним є саме стрімінговий запис, коли дані надходять у BigQuery у режимі реального часу. Але якщо ви вже використовуєте стрімінг, то, швидше за все, він вам справді потрібен — і тут зекономити не вийде.
Натомість можливості для оптимізації криються у двох інших напрямках — зберігання та обробка даних.
І саме про
Отже, далі я покажу:
- Що з’їдає ваш бюджет?
- Як Google розраховує вартість зберігання ваших даних у BigQuery?
- Масовий аналіз обсягів даних у проєкті
- Перехід на фізичну модель
- Результати на реальних проєктах
- Що варто знати перед переходом
Щоб зацікавити вас читати далі, покажу результат налаштувань із цієї статті:
Як бачите, ми
До речі, для цього не потрібно мати глибокі знання у написанні SQL-запитів, тому наступна інформація буде корисна всім, хто використовує BigQuery (навіть якщо ваше використання обмежується лише підключенням платіжного акаунта).
Якщо у вас є хоча б одна таблиця у проєкті, то ви, напевно, бачили великий набір рядків у розділі Details → Storage Info, який навряд чи привертав вашу увагу.
Але якраз тут і ховається “звір”.
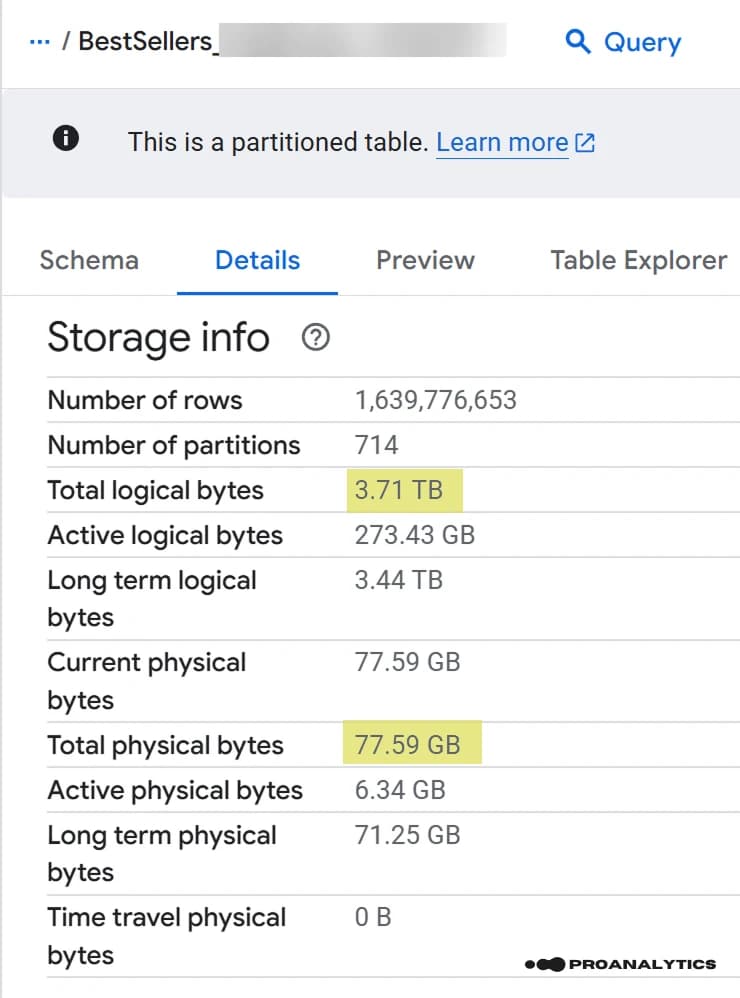
В контексті цієї статті я хочу звернути увагу на два важливі рядки, що стосуються ваших витрат: Total logical bytes та Total physical bytes, і різницю між значеннями у 49 разів (це реальний приклад таблиці в проєкті).
Далі ми розберемо, що вони означають, з чого складаються ці показники та як із ними працювати.
Що з’їдає ваш бюджет?
На цьому етапі ми розглянемо дві основні концепції зберігання:
- Логічна та фізична модель оплати
- Активне та довгострокове зберігання даних
Концепція 1. Логічна та фізична модель оплати
Google розрізняє дві моделі оплати (storage billing models): логічну та фізичну. У першому варіанті оплата нараховується за зміст таблиць, у другому — за фактичну вагу (після стиснення).
Проведу аналогію на прикладі книги:
Логічні байти — це кількість символів у книзі (чиста інформація).
Фізичні байти — це її вага на полиці (вагу можна коригувати за рахунок зміни шрифтів і підбору оптимального паперу).
Уявіть, що ви купуєте книгу і маєте вибір: заплатити або за символи у книзі, або ж за її вагу. Зрозуміло, що спочатку не можна точно визначити, що буде вигідніше.
Тому далі ми розберемо всі “за” і “проти”, але перед цим давайте дослідимо ще одну концепцію.
Концепція 2. Активне та довгострокове зберігання даних
У свою чергу кожна з моделей оплати враховує два типи зберігання:
Активне (Active) — це таблиці або їх частини, які змінювалися протягом останніх 90 днів.
Довгострокове (Long Term) — відповідно, таблиці або їх частини, які не змінювалися >90 днів (ціна за “старі” дані автоматично знижується приблизно вдвічі).
Приклад:
Таблицю завантажили 1 квітня і до 1 липня (90 днів) її не змінювали. З 1 липня вона вважається Long Term, і її зберігання тепер коштує у два рази дешевше.
Якщо у таблиці є партиціювання, то ті партиції, які оновлюються або записуються, залишаються активними, а всі інші переходять у довгострокові.
По суті, використання партицій — це теж спосіб економії на зберіганні без зміни моделі.
Як Google розраховує вартість зберігання ваших даних у BigQuery?
Якщо ви вже отримуєте рахунки від Google Cloud Platform, то можна відокремити суму інвойсу саме за зберігання даних.
Щоб побачити цю суму, вам потрібно:
- Перейти у ваш Billing Account Report.
- Застосувати фільтр Service = BigQuery.
- Вивести групування за SKU.
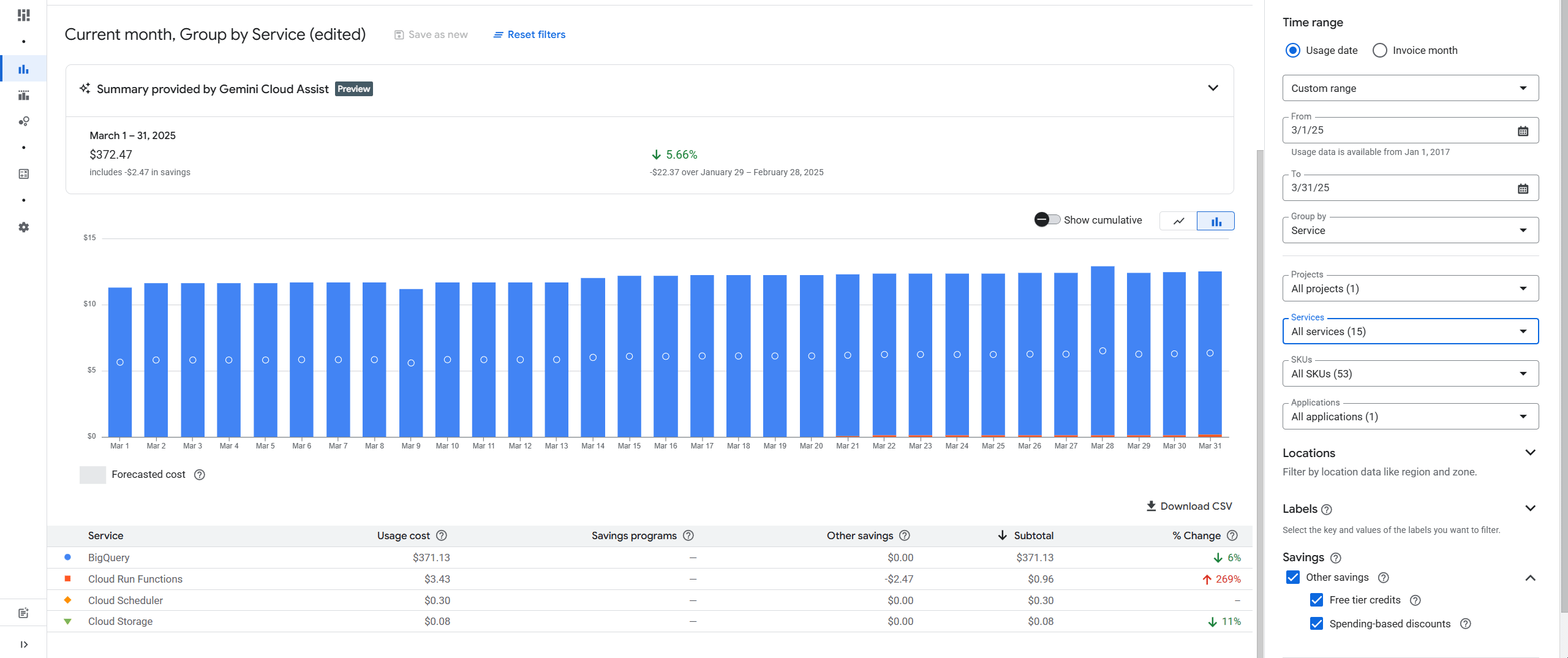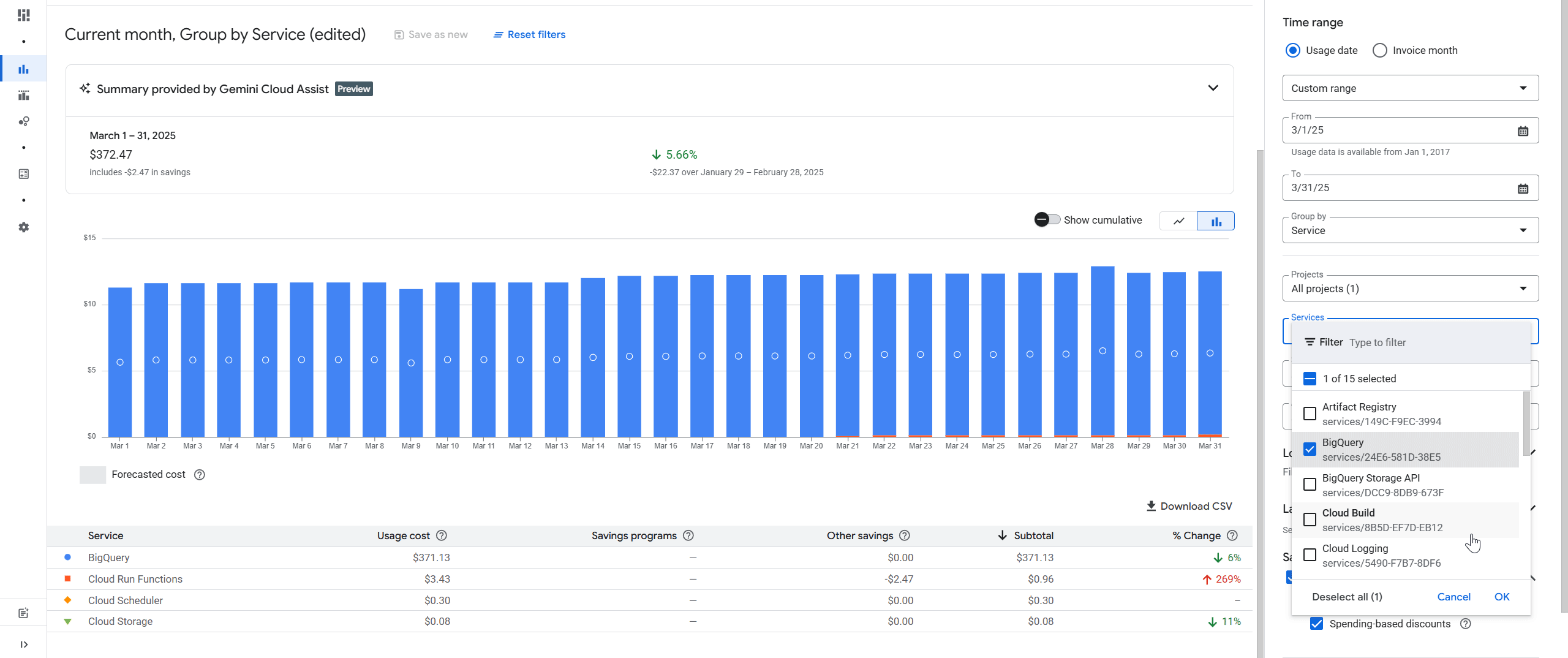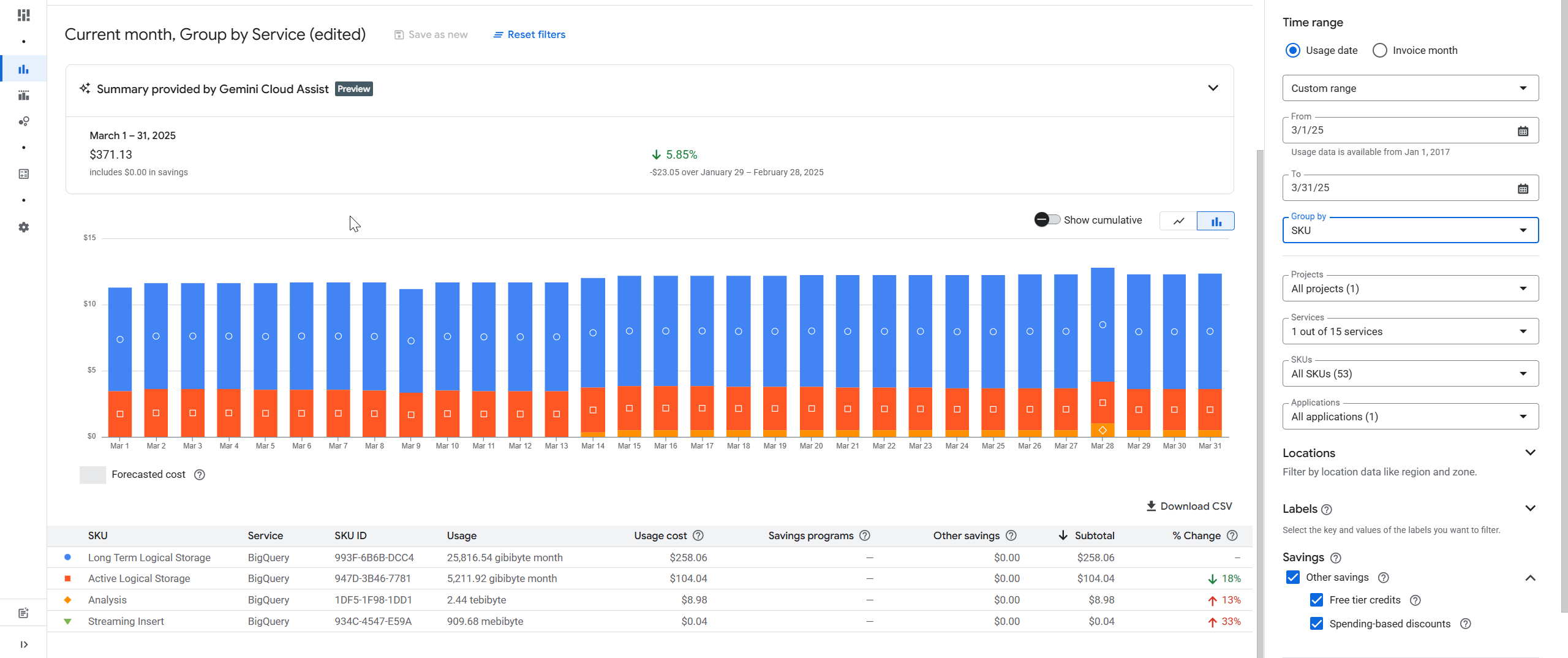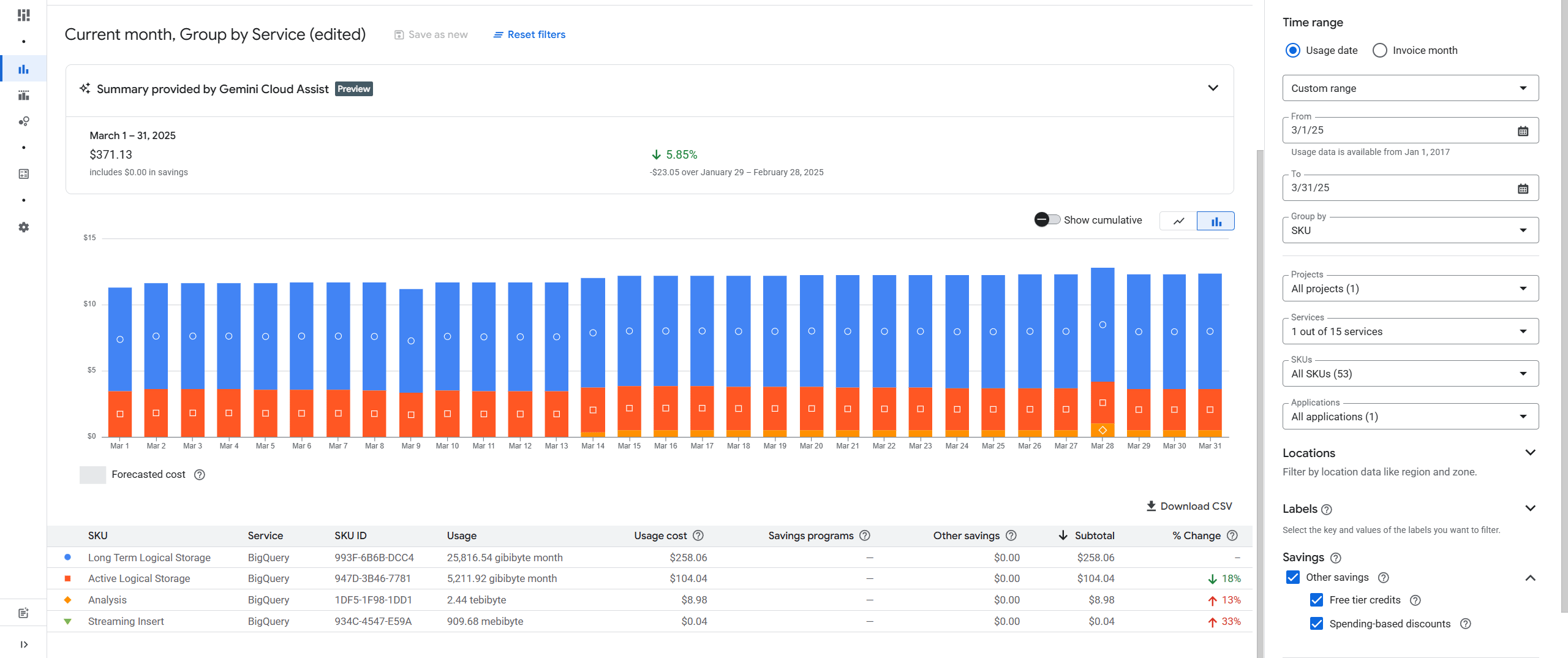
Вуаля — і ви знову бачите вже знайомі Long Term Logical Storage та Active Logical Storage. Це саме ті рядки, які показують вартість
Ціни за зберігання можуть незначно відрізнятися залежно від регіону зберігання.
Для прикладу наведу розцінки за зберігання даних за логічною та фізичною моделями для Європи:
| SKU | Europe (USD/GiB/month) | Коментар |
|---|---|---|
Active logical storage | $0.02 | Перші 10 GiB на місяць безкоштовні. |
Long-term logical storage | $0.01 | Перші 10 GiB на місяць безкоштовні. |
Active physical storage | $0.044 | Перші 10 GiB на місяць безкоштовні. |
Long-term physical storage | $0.022 | Перші 10 GiB на місяць безкоштовні. |
Зараз саме час повернутись до скріна з реальним прикладом таблиці:
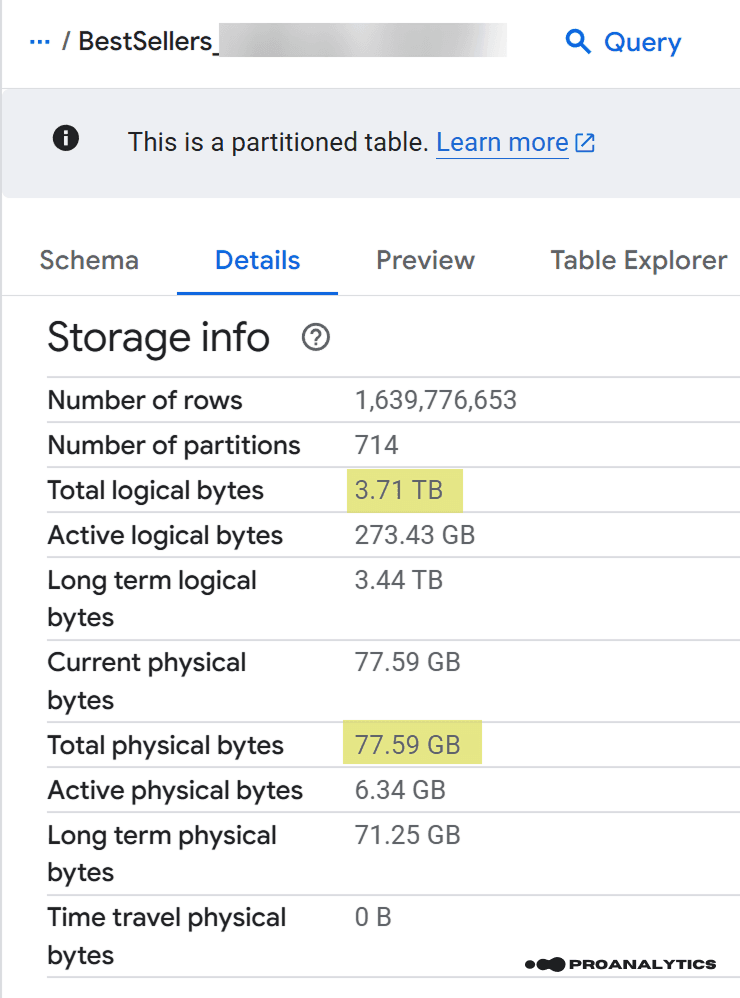
Візьмемо наші об’єми даних зі скріну та порахуємо витрати на зберігання для Europe. Ось який результат ми отримали:
| SKU | Об’єм | Europe (USD / GiB / month) | Витрати за місяць (USD) |
|---|---|---|---|
Active logical storage | 273.43 GiB | $0.02 | $5.47 |
Long-term logical storage | 3.44 TB | $0.01 | $35.23 |
Active physical storage | 6.34 GiB | $0.044 | $0.28 |
Long-term physical storage | 71.25 GiB | $0.022 | $1.57 |
Зверніть увагу: розрахунок виконано без урахування безкоштовних перших 10 GiB.
Давайте підведемо підсумки: у результаті одна й та сама таблиця може обходитися як приблизно у $40 (якщо оплата за логічні байти — $5.47 + $35.23), так і приблизно у $2 (якщо використовувати фізичну модель — $0.28 + $1.57) на місяць. Тобто різниця у 20 разів.
І це лише одна таблиця. На великих проєктах ми використовуємо десятки таблиць, тому різниця в моделі оплати за їх зберігання може бути суттєво відчутною.
Масовий аналіз обсягів даних у проєкті
Звичайно, можна проходити по кожній таблиці окремо й визначати її розміри, але для швидкості краще скористатися запитом, який виведе потрібну інформацію по кожному датасету.
У даному випадку я не відкривала Америку, а взяла за основу скрипт із довідки Google і лише трохи “докрутила” результат.
Власне, сам скрипт, який потрібно використати у вашому проєкті BigQuery:
-- Specify the storage prices for your region for the following 4 variables:
DECLARE active_logical_gib_price FLOAT64 DEFAULT 0.02;
DECLARE long_term_logical_gib_price FLOAT64 DEFAULT 0.01;
DECLARE active_physical_gib_price FLOAT64 DEFAULT 0.044;
DECLARE long_term_physical_gib_price FLOAT64 DEFAULT 0.022;
WITH
storage_sizes AS (
SELECT
table_schema AS dataset_name,
-- Logical
SUM(IF(deleted = FALSE, active_logical_bytes, 0)) / POW(1024, 3) AS active_logical_gib,
SUM(IF(deleted = FALSE, long_term_logical_bytes, 0)) / POW(1024, 3) AS long_term_logical_gib,
-- Physical
SUM(active_physical_bytes) / POW(1024, 3) AS active_physical_gib,
SUM(active_physical_bytes - time_travel_physical_bytes) / POW(1024, 3) AS active_no_tt_physical_gib,
SUM(long_term_physical_bytes) / POW(1024, 3) AS long_term_physical_gib,
-- Restorable (these still cost money as active physical)
SUM(time_travel_physical_bytes) / POW(1024, 3) AS time_travel_physical_gib,
SUM(fail_safe_physical_bytes) / POW(1024, 3) AS fail_safe_physical_gib
FROM
`region-eu`.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT -- change "eu" to your project region; everything else remains unchanged
WHERE
total_physical_bytes + fail_safe_physical_bytes > 0
AND table_type = 'BASE TABLE'
GROUP BY 1
),
cost_calc AS (
SELECT
dataset_name,
-- active + long-term Logical
(active_logical_gib * active_logical_gib_price) AS active_logical_cost,
(long_term_logical_gib * long_term_logical_gib_price) AS long_term_logical_cost,
-- active + long-term Physical
((active_no_tt_physical_gib + time_travel_physical_gib + fail_safe_physical_gib)
* active_physical_gib_price) AS active_physical_cost,
(long_term_physical_gib * long_term_physical_gib_price) AS long_term_physical_cost
FROM storage_sizes
)
SELECT
dataset_name,
-- total for logical model (active + long-term)
ROUND(active_logical_cost + long_term_logical_cost, 2)
AS forecast_total_logical_cost,
-- total for physical model (active + long-term)
ROUND(active_physical_cost + long_term_physical_cost, 2)
AS forecast_total_physical_cost,
-- difference logical - physical (positive = logical is more expensive)
ROUND(
(active_logical_cost + long_term_logical_cost)
- (active_physical_cost + long_term_physical_cost),
2
) AS forecast_total_cost_difference,
-- recommended storage model
CASE
WHEN
ROUND(active_logical_cost + long_term_logical_cost, 2) >0.01
AND ROUND(active_physical_cost + long_term_physical_cost, 2) <0.01
THEN 'PHYSICAL'
WHEN
ROUND( (active_logical_cost + long_term_logical_cost)
- (active_physical_cost + long_term_physical_cost),
2
)/NULLIF( ROUND(active_physical_cost + long_term_physical_cost, 2),0)
> 2
THEN 'PHYSICAL'
ELSE 'LOGICAL'
END AS recommended_storage_model,
FROM cost_calc
ORDER BY
-- sort by datasets where active storage is currently more expensive
(active_logical_cost + active_physical_cost) DESC;Зверніть увагу: розрахунок виконано без урахування безкоштовних перших 10 GiB.
Щоб цей запит вивів результат, вам потрібно мати доступ на рівні BigQuery Metadata Viewer. Навіть загальний рівень Owner не надасть цю інформацію, тому потрібно окремо додати саме цю роль.
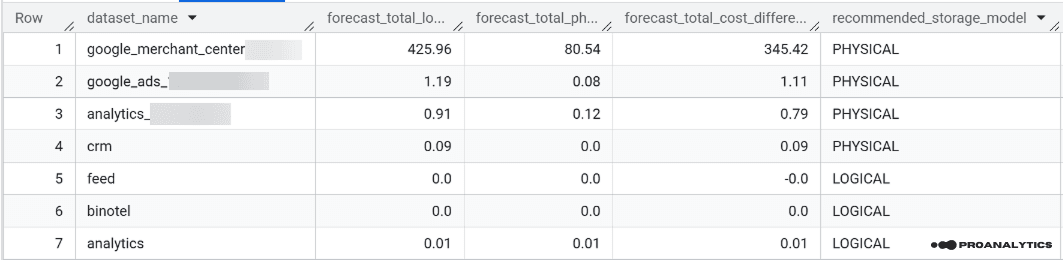
У результаті цього запиту ви отримаєте таблицю з такими колонками:
- Назва датасету
- Прогнозована вартість за логічні байти
- Прогнозована вартість за фізичні байти
- Різниця у вартості між моделями оплат
- Рекомендована модель зберігання для кожного датасету
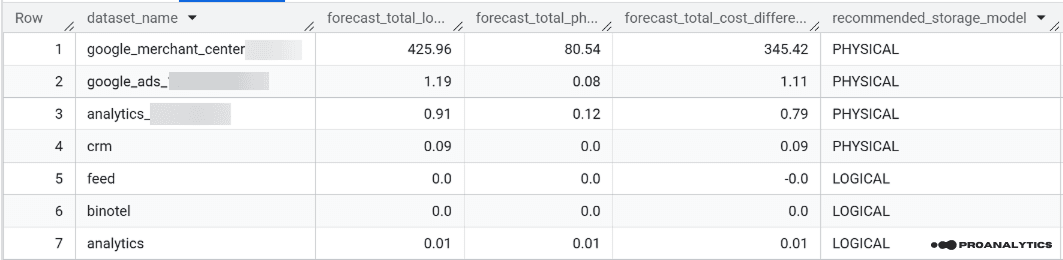
Рекомендована модель зберігання формується на основі різниці у вартості й пропонує перехід на Physical у випадках, коли логічна вартість більша у 2+ рази за фізичну.
Поріг у 2x закладено навмисно — це середня різниця у вартості між логічною та фізичною моделлю зберігання в BigQuery.
Перехід на фізичну модель
Наступним кроком, на основі результатів отриманої таблиці, вам потрібно налаштувати датасети, для яких рекомендована модель — PHYSICAL.
Існує кілька способів, як це можна зробити, але я покажу два з них, які вважаю найпростішими.
Спосіб 1. Через консоль BigQuery
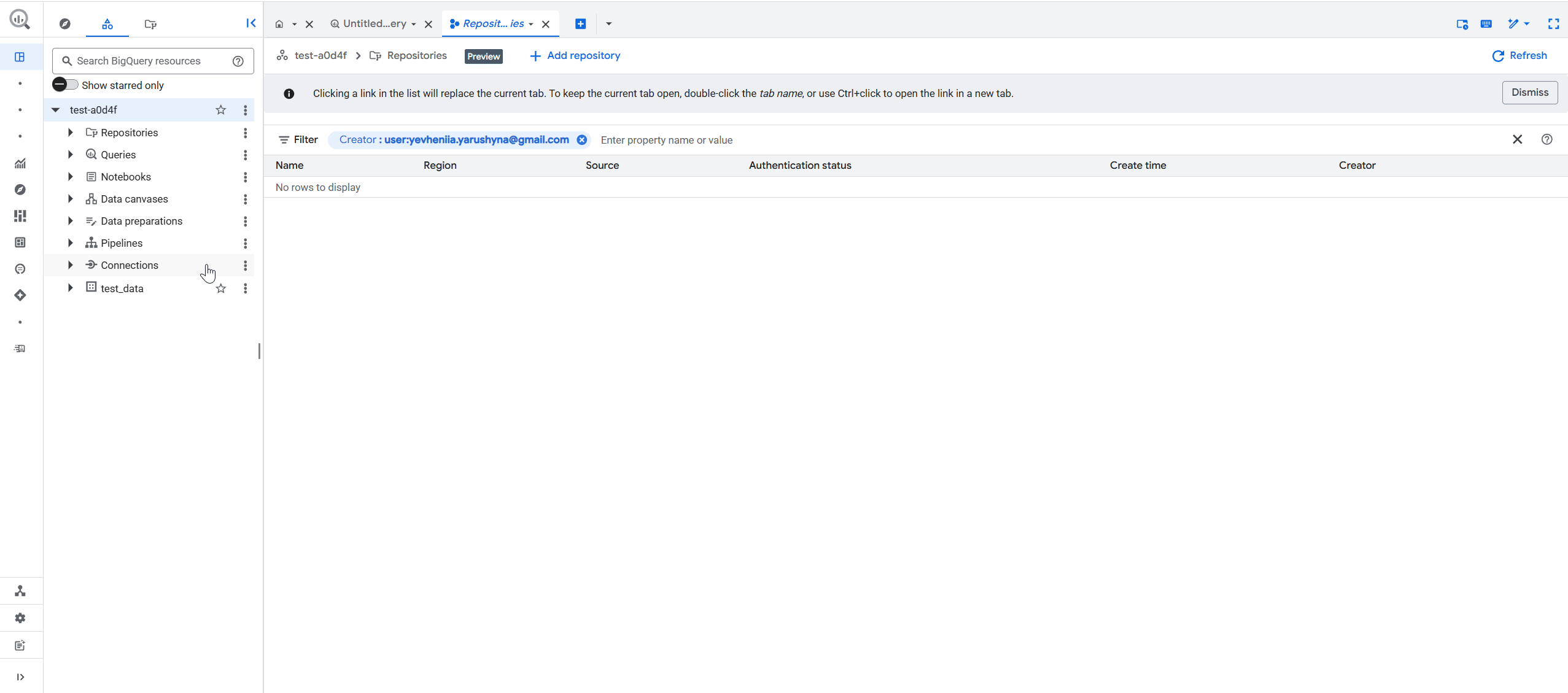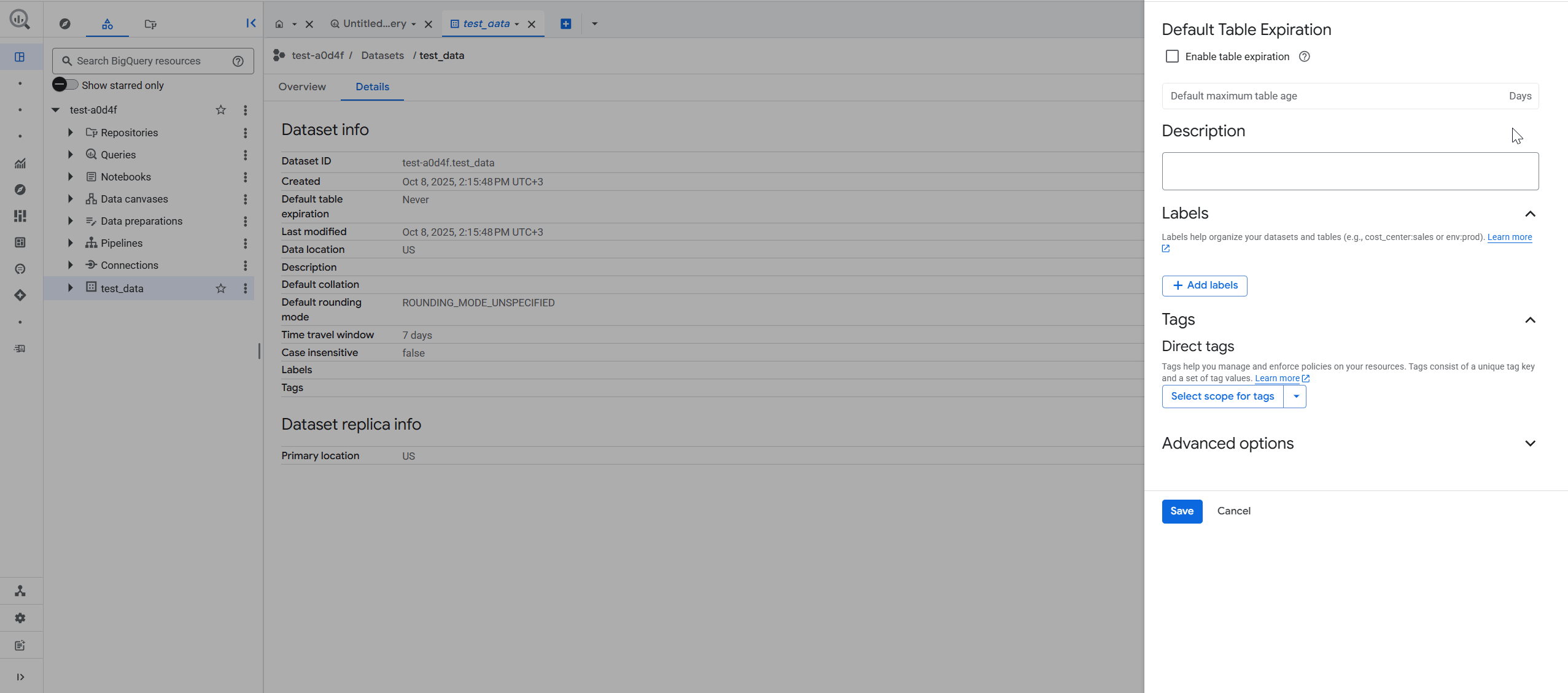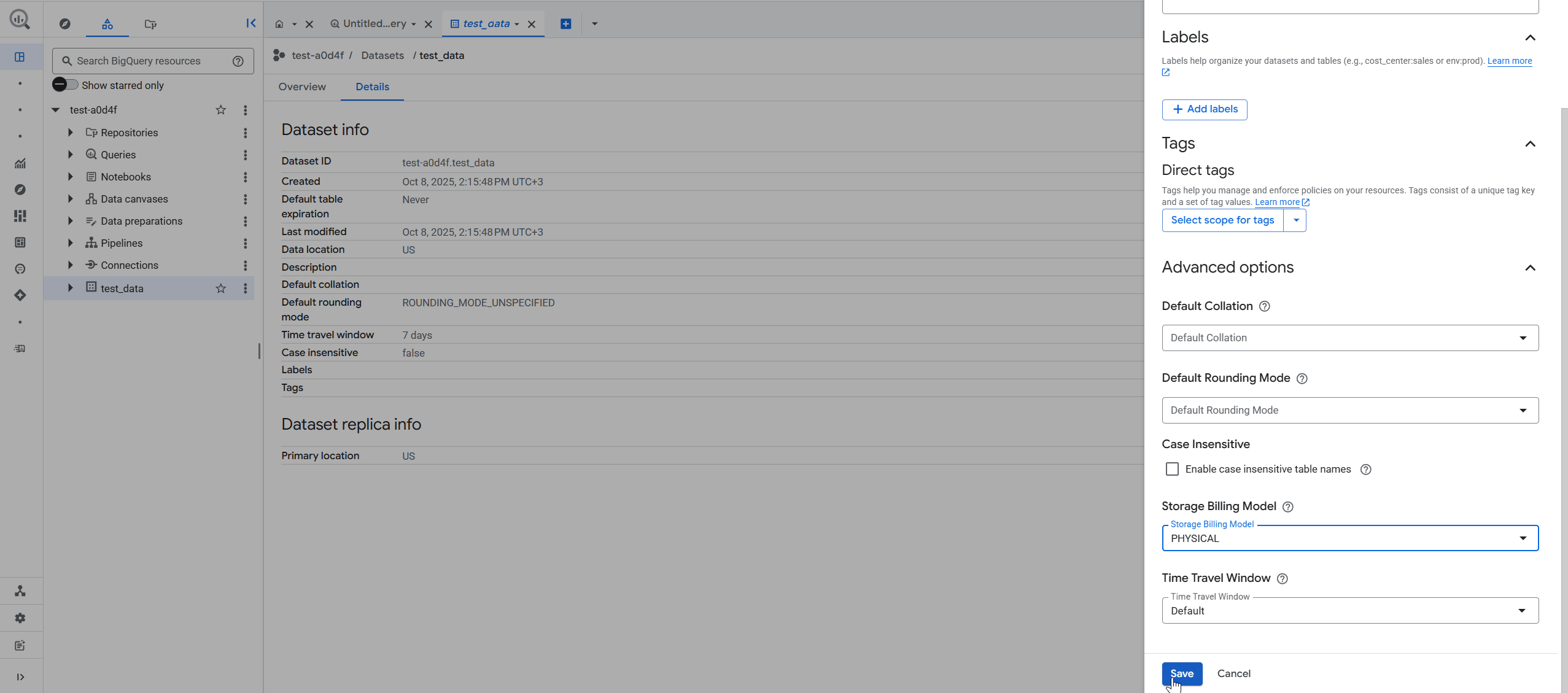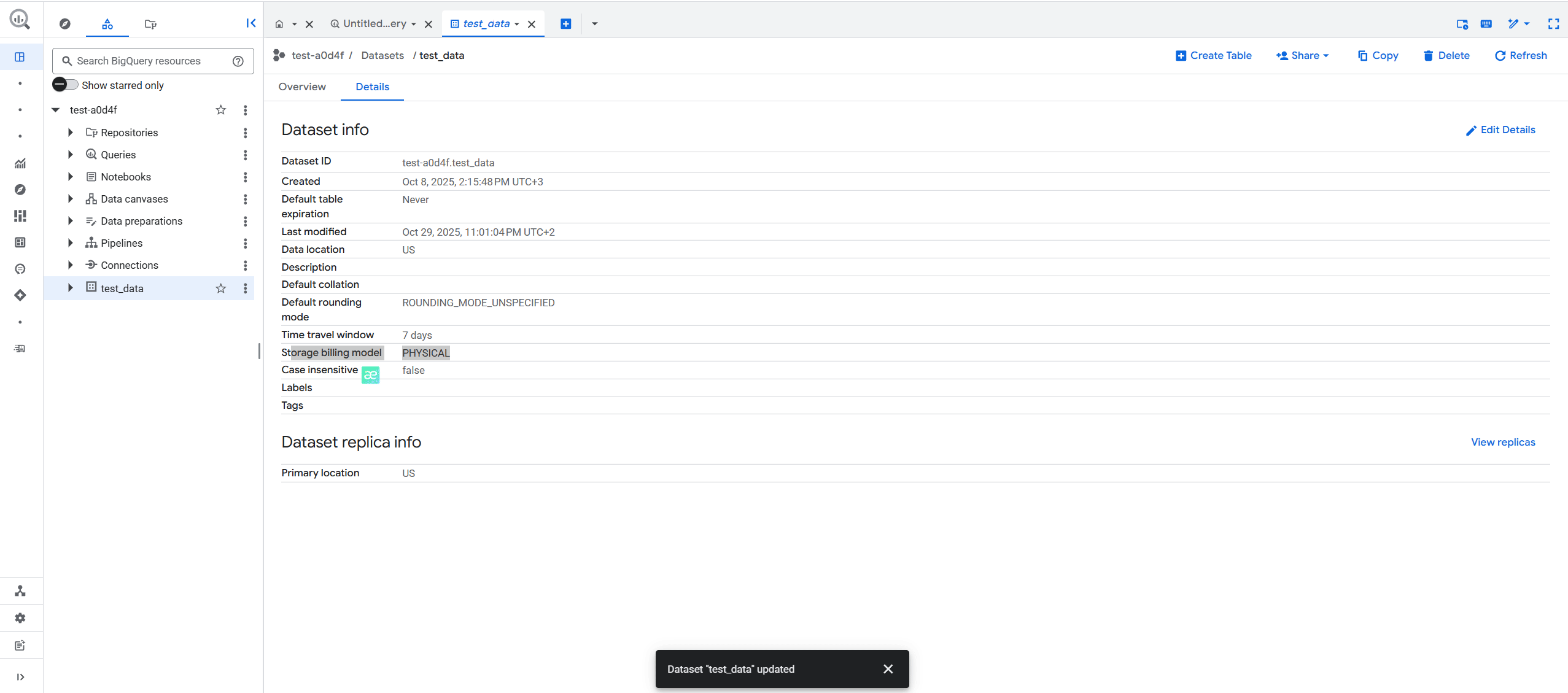
- Клікніть на датасет, який плануєте перевести на фізичну модель.
- Перейдіть на вкладку Details.
- Клікніть на кнопку Edit Details.
- Розгорніть Advanced Options.
- Оберіть із випадаючого списку Storage Billing Model варіант PHYSICAL.
- Клікніть на кнопку Save.
Спосіб 2. Використання SQL-запиту
ALTER SCHEMA DATASET_NAME
SET OPTIONS(
storage_billing_model = 'physical'
);У запиті вам потрібно буде змінити DATASET_NAME на ваш датасет (для кожного окремо), який ви хочете змінити.
Рекомендую через кілька днів після цих налаштувань зайти у білінг-акаунт і перевірити, як змінилися ваші витрати на зберігання даних.
Якщо ви все зробили правильно — цифри мають приємно вразити.
Можливо, одразу ви не відчуєте суттєвої різниці у рахунках, але все одно це крок до оптимізації витрат, що з часом може зекономити значну суму.
Результати на реальних проєктах
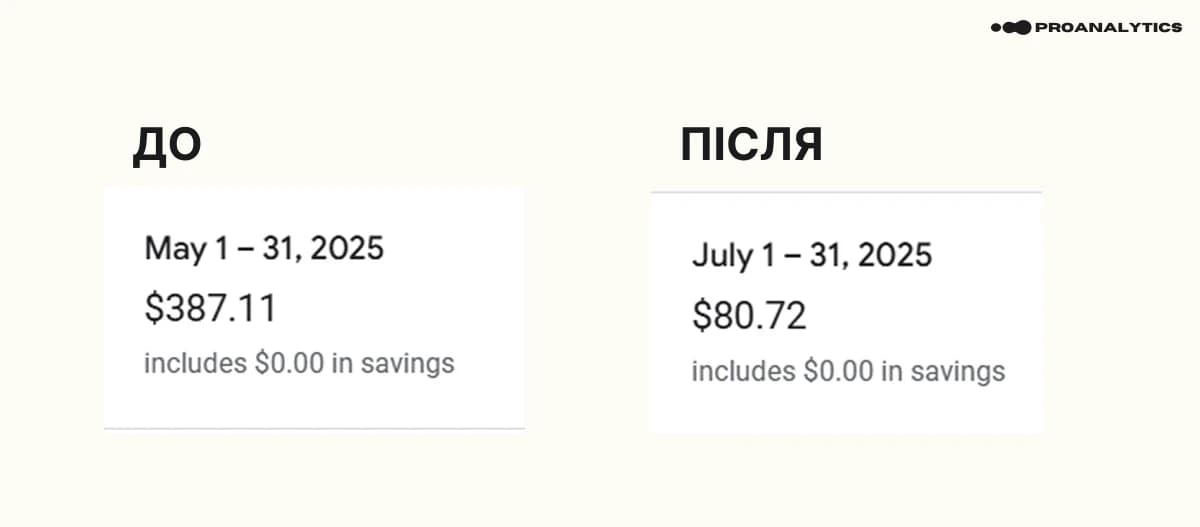
Вище я вже використовувала як приклад дані з цього проєкту. Але продублюю результати по вартості зберігання ще раз — різниця в 300+ доларів на місяць.
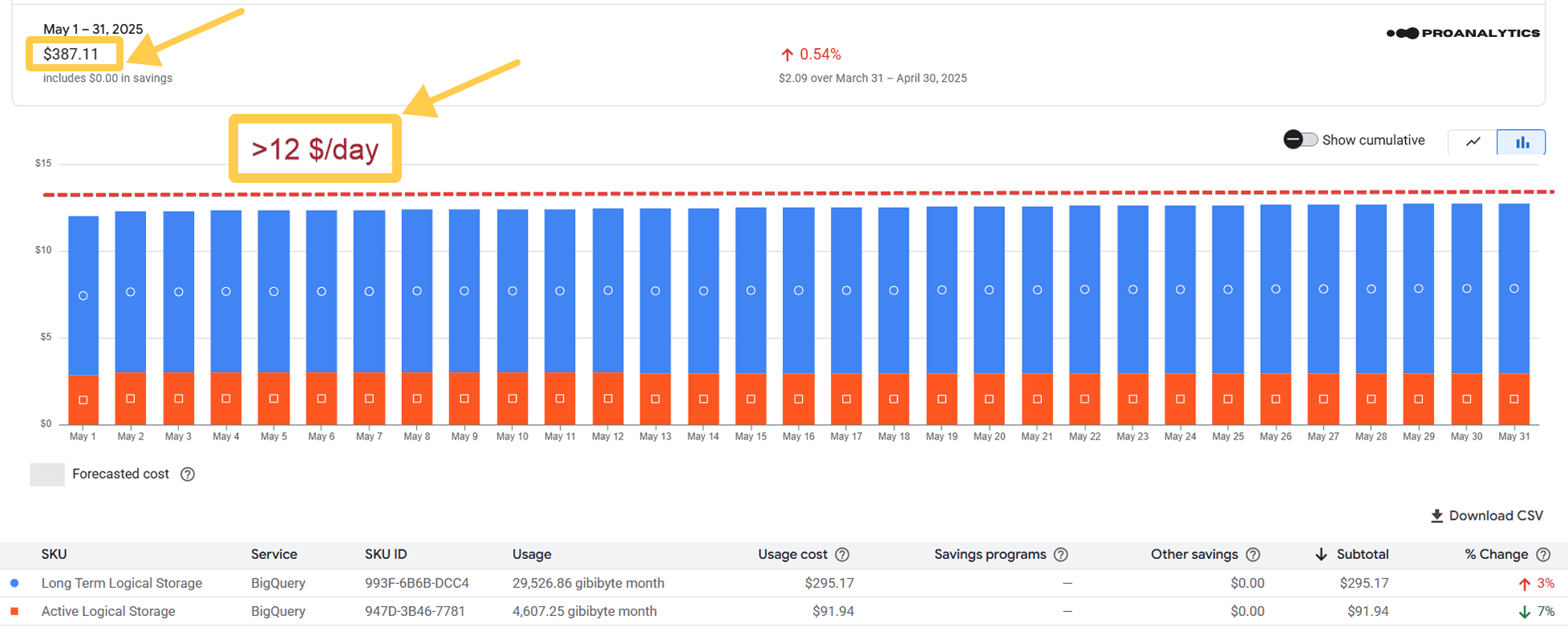
Також додам дані з білінг-акаунта до налаштувань (травень 2025 року):
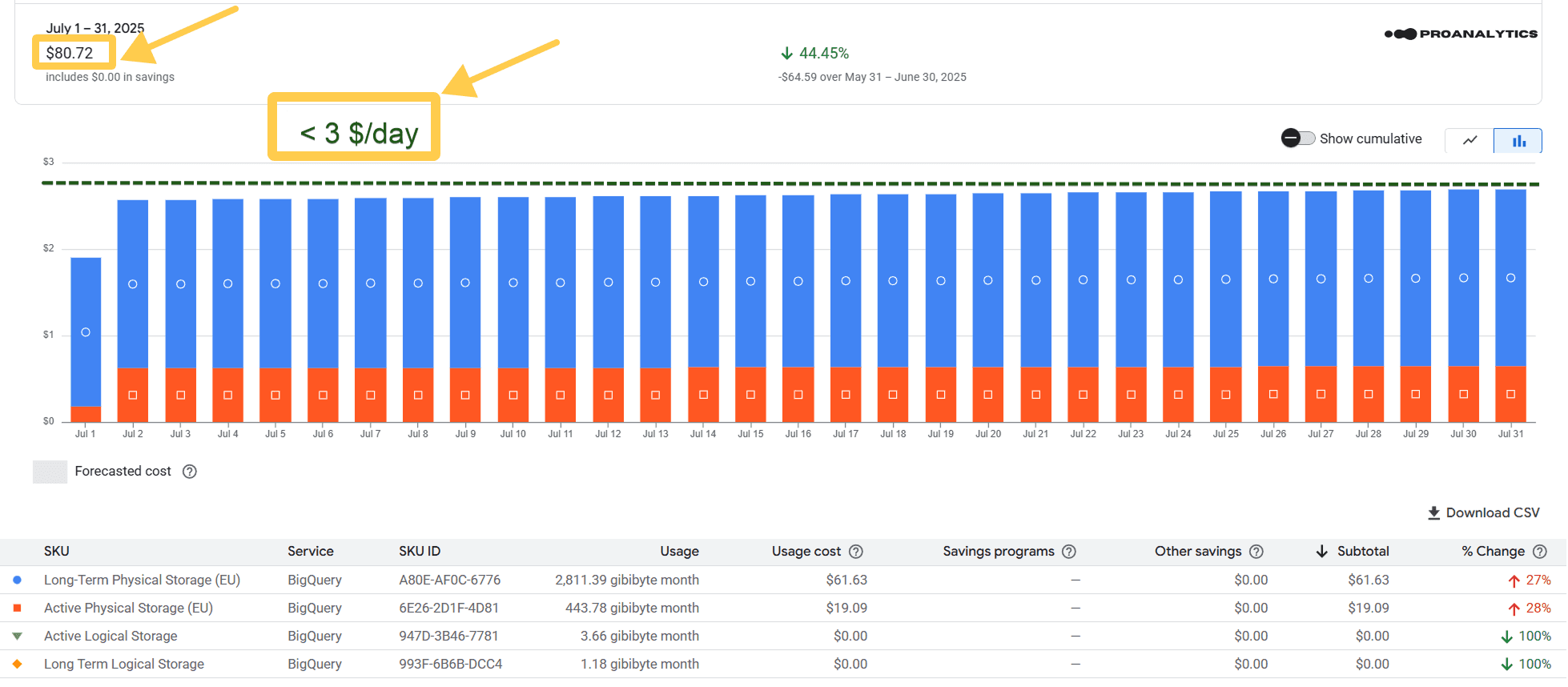
Скрін за повний місяць після налаштувань (липень 2025 року):
Було: $387.11
Стало: $80.72
У цьому прикладі я не даю скрін за червень, тому що всередині червня ми зробили перехід на фізичну модель. Відповідно, результат видно лише частково (за другу половину місяця). Тому я показала зміни на даних за перший повний місяць після переходу — за липень.
Щоб ви зрозуміли, що це не єдиний випадок, додам приклад ще з одного проєкту:
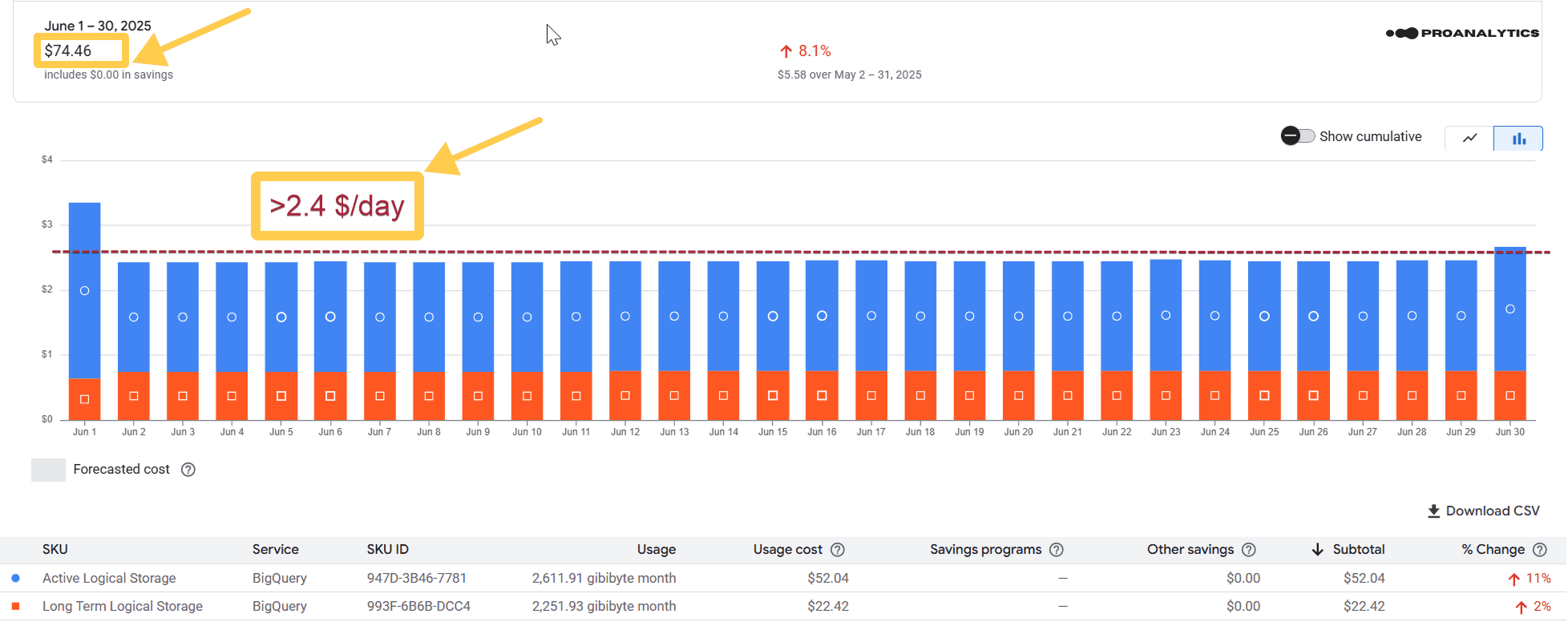
Скрін за повний місяць до налаштувань (червень 2025 року):
Скрін за повний місяць після налаштувань (серпень 2025 року):
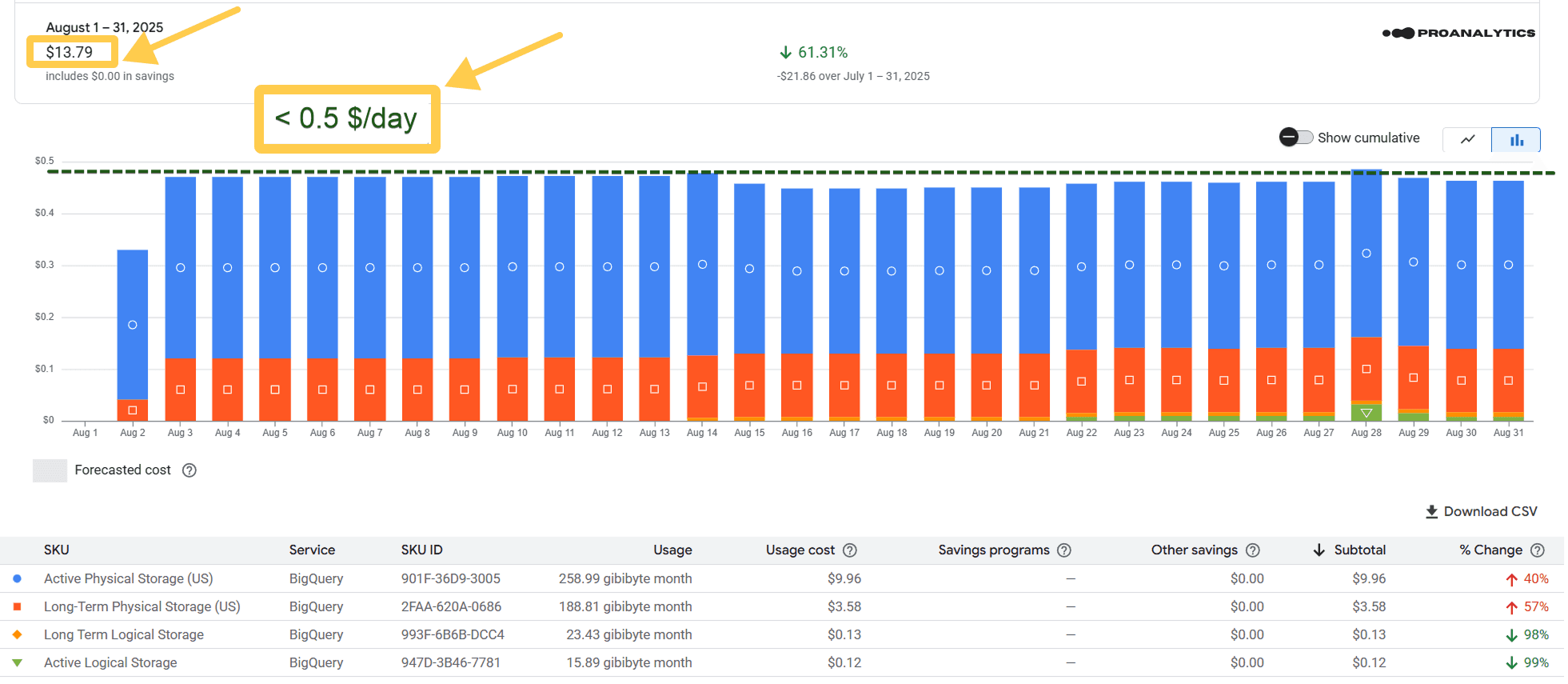
У цьому прикладі я не даю скрін за липень, тому що всередині липня ми зробили перехід на фізичну модель. Відповідно, результат видно лише частково (за другу половину місяця). Тому я показала зміни на даних за перший повний місяць після переходу — за серпень.
Було: $74.46
Стало: $13.79
Не впевнена, що потрібно ще щось додавати — цифри, як завжди, говорять самі за себе.
Що варто знати перед переходом
Здається, що має бути якийсь підводний камінь, але такого немає. Google описує цю ж логіку оплати у своїй довідці, і кожен користувач може нею скористатися. Це якраз чудовий привід читати довідки з першоджерел.
Але все ж є певні технічні нюанси, які варто врахувати:
- Змінити Storage Billing Model можна лише на рівні датасету (не таблиці), тому у нашому SQL-запиті ми також вивели дані в розрізі датасетів.
- За замовчуванням для всіх датасетів у проєкті буде обране STORAGE_BILLING_MODEL_UNSPECIFIED, але фактично ви вже платите за логічні байти (та сама LOGICAL модель).
- Якщо ви зробили перехід на фізичну модель, а потім захочете повернутися назад — ви можете це зробити, але лише через 14 днів після зміни.
- І ще раз нагадаю: щоб SQL-запит із цієї статті видав результат, потрібно мати доступ певного рівня — BigQuery Metadata Viewer.
Перехід на фізичну модель — це один із найпростіших способів оптимізувати витрати на BigQuery без будь-яких ризиків і без зміни логіки роботи даних. Різниця може здатися невеликою спочатку, але в масштабі кількох місяців або десятків таблиць — це суттєва сума.
Простими словами — це “розумна економія”, яку Google сам пропонує, просто не всі до неї ще дісталися. І, звісно, це не єдиний спосіб економити на BigQuery. Хочете платити менше — звертайтеся ;)
Коментарі
Поділися думкою та постав запитання
Завантаження коментарів...